一. 前言
上一部分添加了熔断器Hystrix,并且了Dashboard和Turbine进行可视化。但是Turbine直接硬编码在yml上,与服务代码高度耦合,所以并不是一个良好的设计,还需要进行改进。
二. 使用RabbitMQ作为消息中间件
使用Hystrix.stream可以让使用了Hystrix功能的Service得到监控,而Turbine与Dashboard可以很好地收集和可视化这些监控数据。但有一个问题是,Dashboard还好,与Hystrix.stream没有任何耦合,只需要输入待定URL即可。而Turbine在上文是直接硬编码到yml中,指定要获取哪个或者哪些Service的监控信息,已经属于高度耦合了。即使不考虑性能,这也会出现问题,当Service与Turbine网络不通,此时就无法进行工作。而增加一个MQ,可以使得Service只需把数据丢给MQ,然后Turbine从MQ上获取数据即可。如果出现问题,可以很好地定位到:Hystrix端的问题?Turbine端的问题?MQ的问题?Hystrix与MQ的连通问题?Turbine与MQ的连通问题?
RabbitMQ简要知识
RabbitMQ是一个基于Erlang的消息队列,遵从AMQP协议(消息队列的一个协议)
Erlang是一种面向并发的编程语言。
RabbitMQ的管理方法有很多种,修改配置文件,命令行CTL,可视化管理界面。
常用的命令就是:rabbitmqctl
顺手把rabbitmq也配置到了环境变量里,记录一下,是要配置到Path里,而不是ClassPath。。然后好像是用户变量跟系统变量是差不多的,反正这台电脑就一个用户。
使用可视化管理界面,先安装该插件:
rabbitmq-plugins enable rabbitmq_management
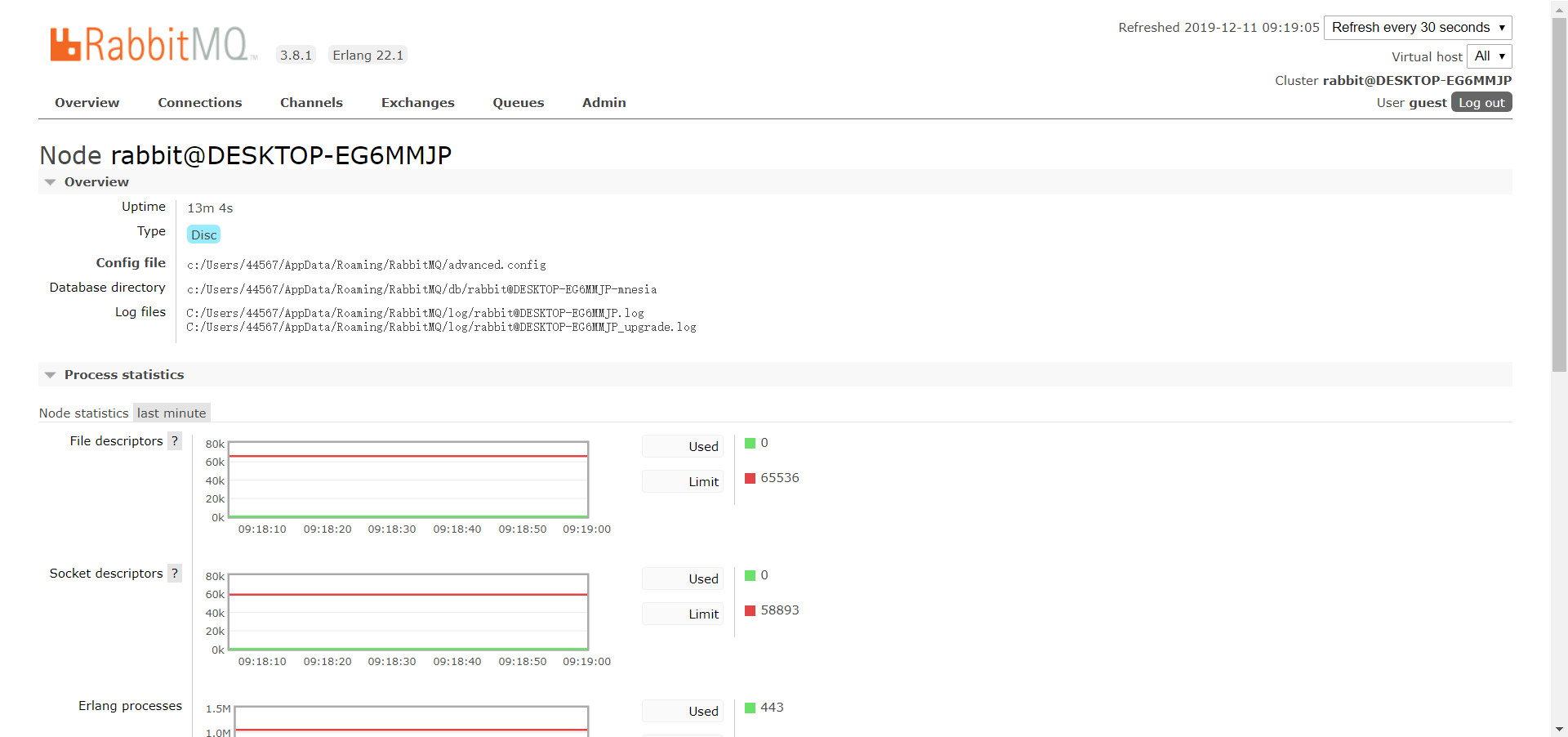
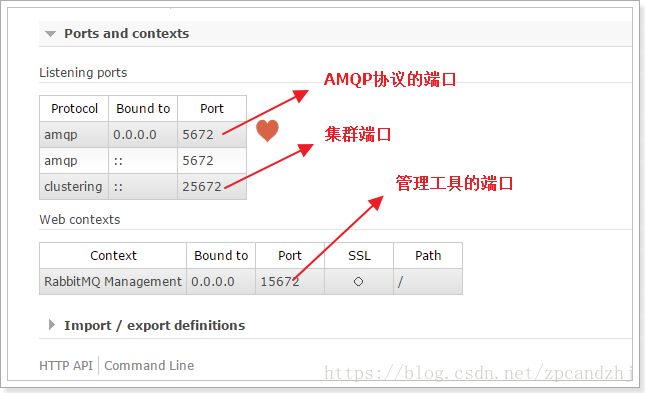
之后这个插件就会默认注册到15672端口,打开localhost:15672就可以看到。而且rabbitmq服务是自动启动的,无须自己手动启动,然后再使用。效果图:(默认账号密码: guest , guest)

点一下Node:
使用步骤
①改写微服务Service
之前的做法是,给Service添加一个Hystrix.stream结点,使用@EnableCircuitBreaker表示启动监控,并且把监控数据存储到Hystrix.stream结点。但现在我们要把数据存储到MQ,所以先导入MQ的依赖:
1 | <dependency> |
为什么需要导入这么多个依赖?书上跟网上的教程都只写了2~3个依赖。这也是最困惑我的地方,只能解释为版本的问题了。其实上面有一些依赖我认为是可以去掉的,但我去掉了之后会导致项目无法启动,所以就懒得去深究如何简化导入依赖了。
依赖这一块我排错了很久,一开始也只是导入了2~3个依赖,然后maven也没有报错,代码也没有报错,此时启动却失败,先看大概的错误信息:
Fail to parse configuration class: xxxx/xxx/xx/RabbitAutoConfiguration …
一开始没把这个当回事,其实一长串的错误,这个是第一个,应该好好研究一下的。最后找到了这个类,一点进去:
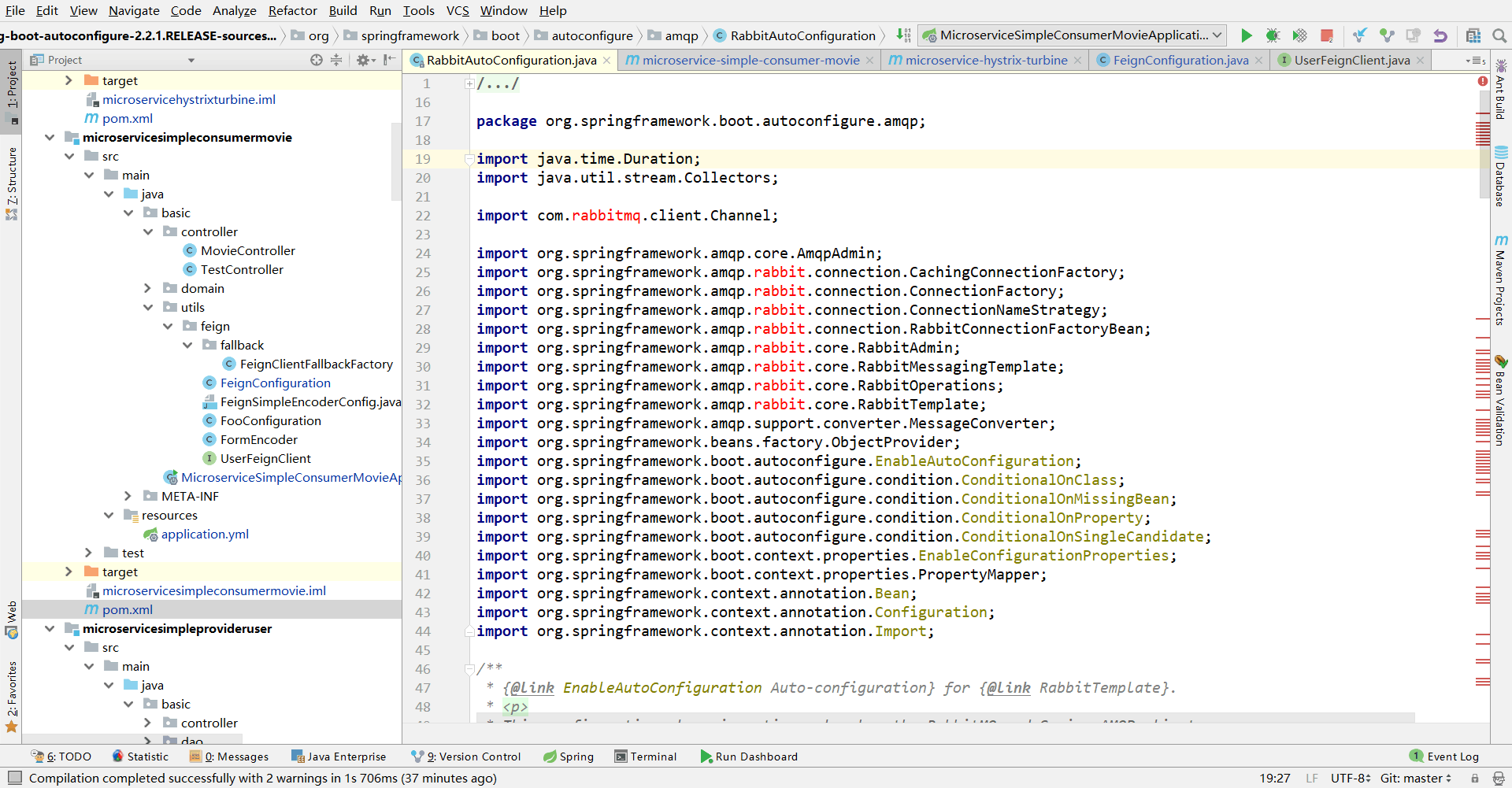
原来是还有一些包没导入完全,所以这个类当然会出错了,于是也就无法加载了。这时点进本地的maven仓库看了一下,这个包并没有下载完全(连完整的jar包都没有,只有.jar.part这种)。当时其实挺无语的,竟然还能偷懒?于是把它删了重下,才下好了完整的jar包。这时候依然报错,于是把依赖删掉了再写回去,就好了(算是认识到了,这就是IDEA的一个bug,当你的maven下载jar包的时候出现问题,但它可能会误以为你已经成功下载好了。然后你重新下载了之后,它还是无法识别,会显示错误,这时候把依赖去掉,再重写,可能就会解决)。
之后,关于依赖包这一块,感觉调用轮子最复杂的步骤估计就是依赖包的处理的。一个依赖包其实内嵌依赖了其他的包,并不仅仅是那一个包的。然后不同的包之间可能依赖版本不同,这时候就会导致冲突而报错。所以依赖包与版本管理确实是很麻烦的一个事情。
依赖包的版本冲突问题处理好之后,启动依然报错:
A default binder has been requested, but there is no binder available
然后网上都说要加依赖包spring-cloud-stream-binder-rabbit,可是查看maven管理,会发现它其下一个类也不需要用到。结果加上之后启动成功又用到了。。所以,IDEA的bug真的挺多的,有时候确实是代码存在问题,但也有可能是IDEA本身有问题。
依赖包问题彻底解决之后,启动类加上:
@EnableAutoConfiguration(exclude = RabbitAutoConfiguration.class)启动成功。
(这个exclude可以不需要)
②改写Turbine
之前的Turbine也是硬编码来表示要监控哪些Service,然后通过配置也是指明要监控它的哪些结点,比如是hystrix.stream.为了解耦,需要给Turbine连接到MQ,作为Consumer的角色。
先导入依赖:
1 | <dependency> |
记住要去掉spring-cloud-starter-netflix-turbine,因为turbine与turbine-stream不兼容。
启动类的@EnableTurbine改成@EnableTurbineStream。
yml关于turbine的配置去掉(因为现在是使用TurbineStream,而非Turbine)
启动成功。
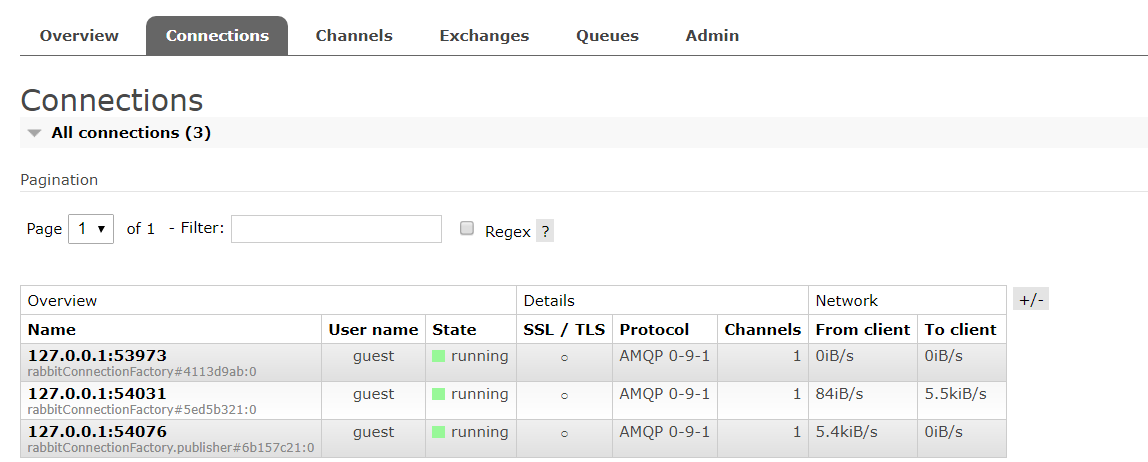
③测试,turbineStream确实在打印信息,但并没有任何有意义信息。再到RabbitMQ的管理界面一看,确实是Producer成功把信息提交到了MQ,但Consumer(也就是这里的TurbineStream)却没有读取,可以看到一共有3个Connections跟Channels(不明白为什么Producer的Connections的数量有两个),Queue有1个(就是用于存放和获取信息的队列),但显示是idle,因为Consumer没有去获取数据。
解决方法:显式指明Producer要提交到哪个Queue(可以自定义),然后显式指明Consumer要到哪个Queue去获取数据。可能是以前的版本都有一个默认,而新版本去掉了默认,或者二者默认不一致了(毕竟Turbine已经没有维护,而RabbitMQ还在维护),导致了失败。
Producer的yml:(关键在于增加一个spring-cloud-stream-bindings-hystrixStreamOutput-destination
1 | spring: |
Consumer的yml: (对应的,turbineStreamInput。 一开始错写成hystrixStreamInput。。。)
1 | spring: |
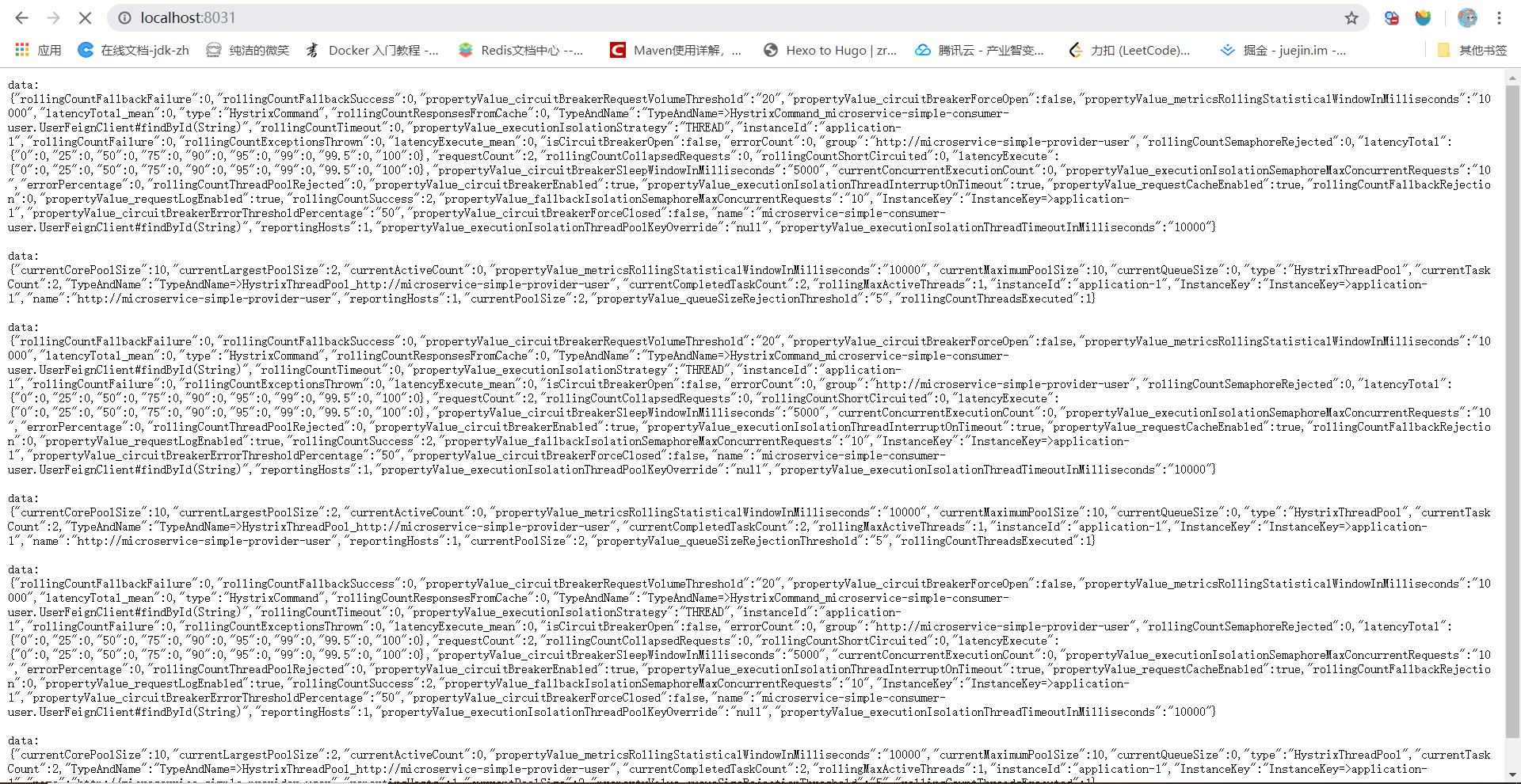
启动,看到RabbitMQ的queque状态不再是idle,而是running。再看turbine,确实已经获取到了Producer提交到MQ上的数据。完成。
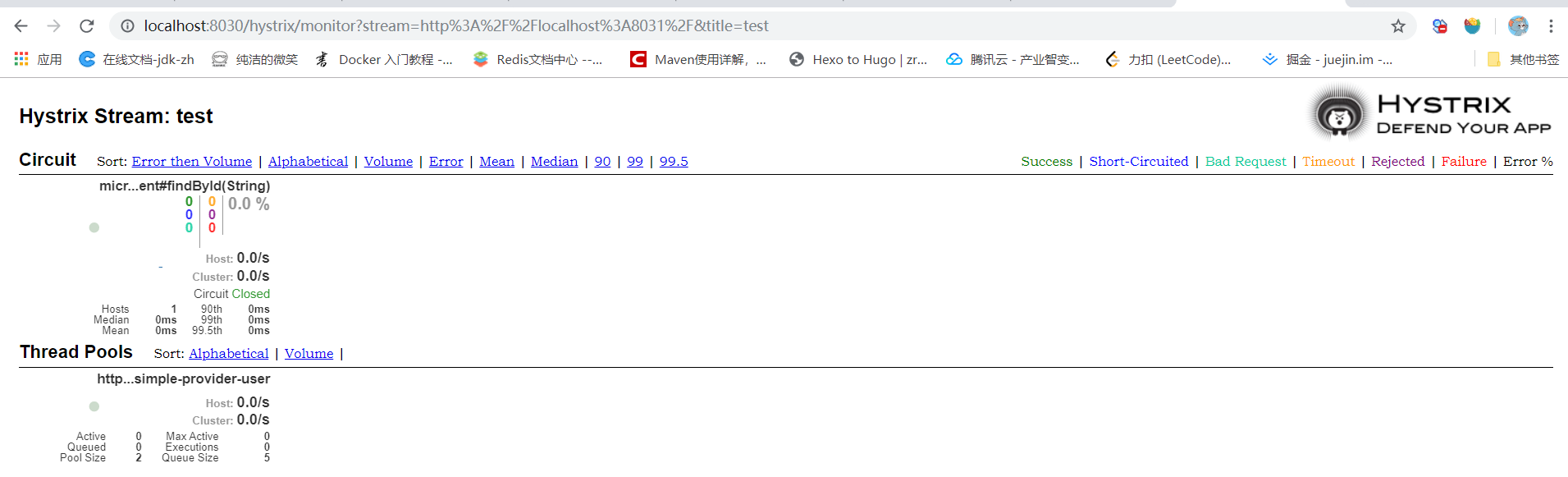
效果图:
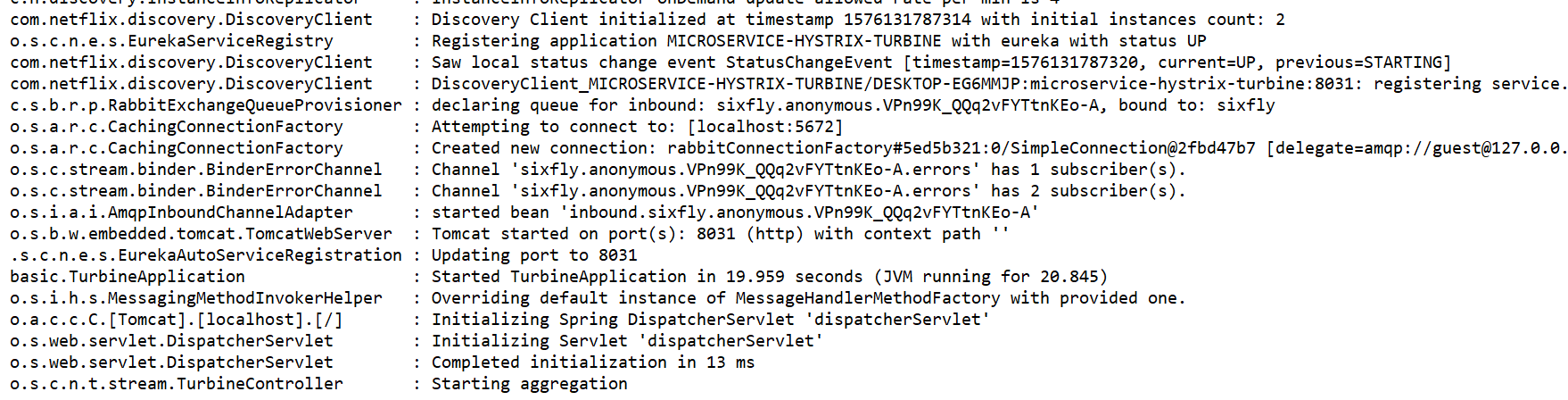
Turbine启动就已经看到,连接到了RabbitMQ,且连接到了具体的Queue,获取到了数据:
查看RabbitMQ Management UI:
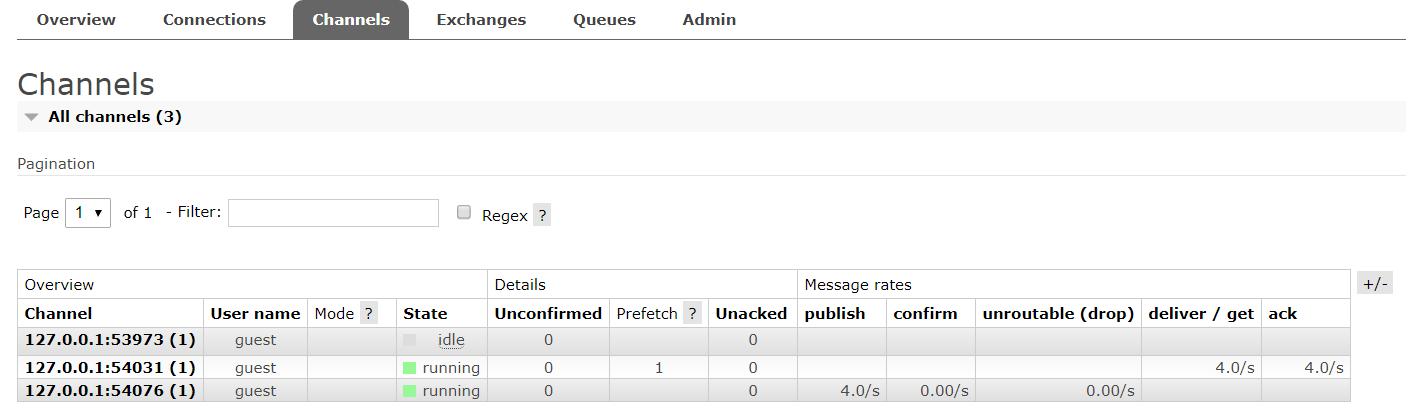
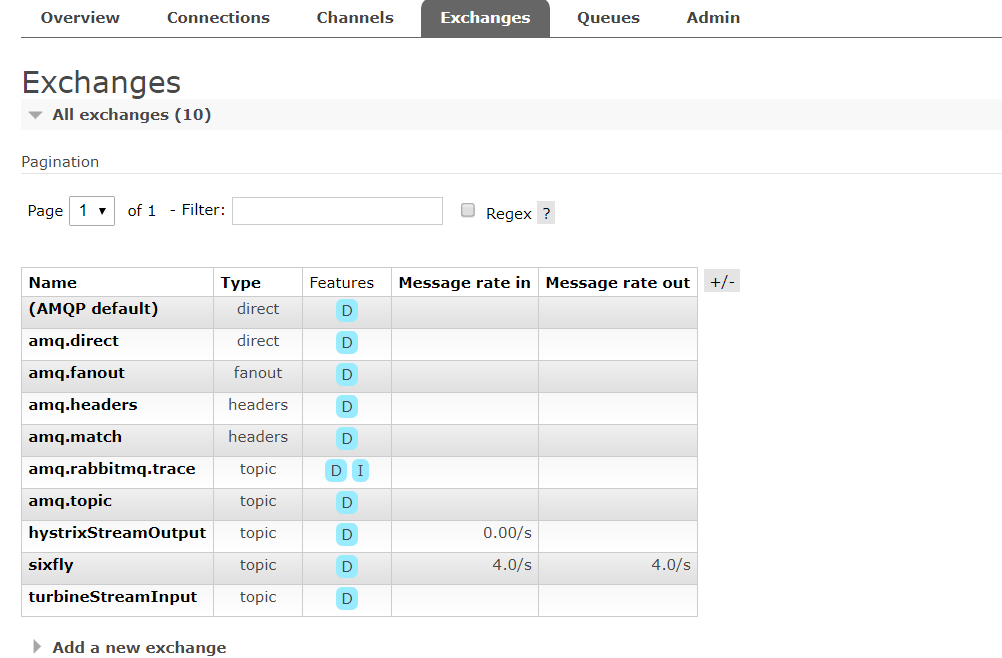
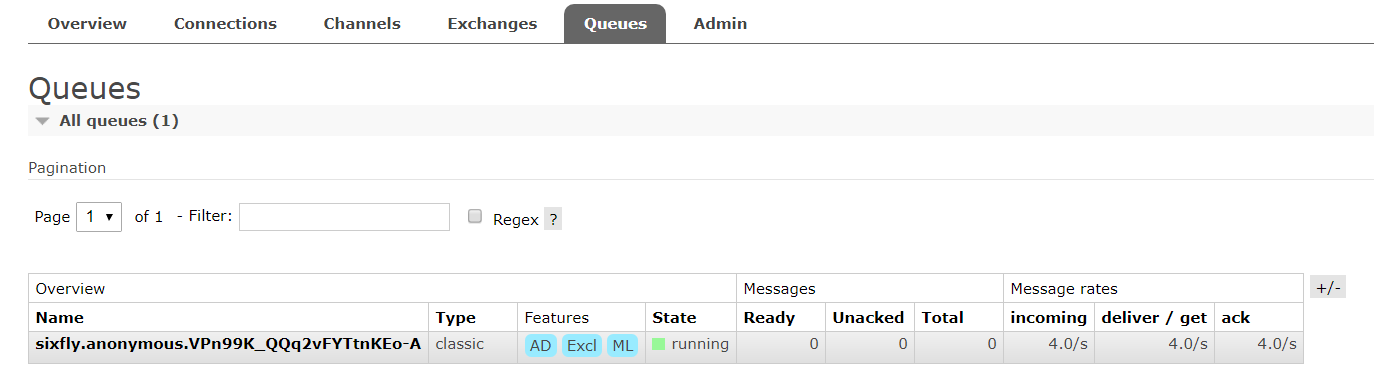
Turbine获取到了数据:
Dashboard没有任何更改,可以获取Turbine的信息并可视化: