一. 前言
本文的最终解决的问题:如何判断一条SQL语句用到了哪些锁?
(特别地,这里考虑的是MySQL数据库的锁机制)
首先,我们需要先对MySQL的事务机制,锁机制,索引机制都总结一遍。
二. 事务隔离级别:
RU:Read UnCommitted
RC:Read Committed
RR:Repeatable Read (default)
Serializable
总结:
RU可以读取未提交的数据,因此存在脏读的问题。
RC只能读取已经提交的数据,因而解决了脏读的问题,但存在不可重复读的问题
RR保证了可以重复读的问题。
RR与Serializable都解决了大部分的问题,因此默认就是RR。(当然,在需求高性能的情况下,会使用RC)
查看MySQL的隔离级别:select @@tx_isolation 查看当前会话的事务隔离级别select @@global.tx_isolation 查看系统全局的隔离级别
设置隔离级别:set session/global transaction isolation level xx;
(xx can be read uncommitted, read committed, repeatable read, serializable)
三. 锁机制:
MySQL锁的类型:(有多种分法)
①根据锁的兼容情况,可以分为4种:
Shared locks,Exclusive locks(共享锁,排他锁,即S锁,X锁,在其他数据库也有这两种)
Intention Locks:意向锁,分为共享意向锁IS,共享排他锁IX锁。(作用后续说,针对MySQL的行锁而出现)
②根据锁的锁定范围,可以分为三种:
表锁 Table Locks,行锁 Record Locks,页锁 Page Locks
(在MyISAM中为Table Locks,而在InnoDB中只有Record Locks。Page Locks存在于BerkeleyDB)
表锁和行锁的区别:
表锁的开销较小,不会产生死锁,锁定范围大,但并发度最低
行锁的开销较大,可能产生死锁,锁定范围较小,并发度更高
页锁此处不解释(我也不会)
③InnoDB下的Lock Type:
由于目前重点使用的MySQL引擎一般是InnoDB,因此对InnoDB进行更细致的了解。
InnoDB的行级锁(InnoDB不存在表级锁,只是在特定情况下看起来像是表级锁的形式而已):
1.Record Locks:A record lock is a lock on an index record. 即锁定一个index的record。
2.Gap Locks:A gap lock is a lock on a gap between index records, or a lock on the gap before the first or after the last index record. 即锁定record之间的的间隙。
(Gap Locks存在于RR与Serializable,不存在于RC。RU一般不会用,不考虑,而且也没有)
3.Next-Key Locks:A next-key lock is a combination of a record lock on the index record and a gap lock on the gap before the index record.(3 = 1 + 2)PS:此处有一个小test,事务隔离级别是与系统全局的设置有关的(即使两个Session transaction isolation level都设置为RC,但如果Global transaction isolation level设置为RR,那么就按照RR的情况来执行,即此时存在Gap Locks。所以不清楚Session level有何作用)
不同情况的加锁情况:
要考虑这个问题,先整理一些基础知识:
①首先要了解锁之间的兼容性(S锁,X锁,IS锁,IX锁):

PS:这是仅限于Table-level的compatibility,网上传的很多都忽略了这个。
关于意向锁:主要是用于解决行锁和表锁的冲突。试想一下,当事务A锁住了表中的一行(假设为S锁),而事务B需要申请整个表的X锁。那么事务B需要做的事情:
1.判断表是否被其他表锁锁住(无论X,S),这个很简单.
2.判断表中的每一行是否被行锁锁住(无论X,S,因为X与二者均不兼容)。
如果只有X,S锁,那么我们需要逐行检查,如果有1个亿的data,那么就需要查询1亿行。
如果添加了意向锁呢?意向锁的作用方式:
当一个事务需要获取一个行锁的X锁,先获取一个IX锁。
当一个事务需要获取一个行锁的S锁,先获取一个IS锁。
(记住,上面的表格是仅限表锁的情况,如果需要获取表锁的X/S锁,那么不需要获取IX,IS锁。另外,IX,IS锁是数据库后台自动获取的,无须我们显式调用)
这个时候,当另一个事务,要申请X锁,第一步依然是判断是否被其他表锁锁住。
第二步就改成了,判断该表是否存在IX,IS锁。(如果存在IX,IS锁,说明该表存在X,S锁,不管是哪一行)仅仅通过判断是否存在意向锁,就省去了遍历所有行的操作。
(PS:如果另一个事务要申请的是S锁,同样如此,只是不需要判断IS锁,而是判断IX锁)
记住:意向锁与表级的X锁不兼容,但与行级的X锁是兼容的
(不然你先获取了IX锁,如何继续获取X锁呢?)
②数据库的并发控制协议
MVVC:Multi-Version- Concurrency Control。即基于多版本的并发控制协议。
它最大的好处:读操作不加锁,读写不冲突,可以极大地增强并发性。
Lock-Based Concurrency Control。即基于锁的并发控制。
(如果我们每一种操作都需要获取lock,由lock来完全实现并发控制,那么并发性会相当地差。其实也就是相当于Serializable,完全串行化执行。所以现阶段,大部分的数据库都不会是完全的基于lock去实现并发控制,而是实现了MVVC模式)
在MVVC并发控制中,读操作可以分为两种;snapshot read(快照读),current read(当前读)
所谓snapshot,就是系统在某一个时刻的印象,所以此时读取到的不一定是最新的数据,可能是某个历史版本的数据,那么这时候就不需要加锁。(因为本来就不一定是最新的数据,那么两次snapshot read不一致也是很正常的,所以怎么能算是脏读幻读呢(滑稽)!)
current read就不一样了,它就是要读取系统最新的数据,所以此时需要对读操作进行加锁,然后再基于Lock-Based去进行并发控制。
在MySQL InnoDB中,snapshot read又称简单的select,一般形式为:select *from table where ?; # 存在例外,后面分析
current read:select* from table where ? lock in share mode || for update || for share(8.0之后的版本)
(如果直接显式要lock了,那么都lock了,当然就是要current read,而不是读取snapshot了)
insert,update,delete(这些操作当然不能读snapshot,不然你update一个已经被delete掉的数据吗)
(从底层源码来说,update,delete都包含一个current read,而insert,需要检查unique key冲突)
③聚簇索引(cluster index):
这是由MySQL自动生成的一个index(无法人为控制),它一般是直接把主键设置为cluster index,所以又称主键index。
(如果表没有创建主键?那么按照以下规则来创建cluster index:(一般还是要显式给表一个PK)
1.会用一个唯一的非空的index列,作为cluster index
2.如果没有这样的index,那么InnoDB会隐式生成一个主键来作为cluster index
其他人为定义的索引,称为辅助索引(secondary index),也可以称为非聚簇索引。
关于这两个index的具体区别,查找时的路径有何不同,可以参考这篇文章:
https://www.cnblogs.com/rjzheng/p/9915754.html
关键点:每创建一个index,那么就会生成一个B+树,因此index不能乱加,会导致index的时候需要同时维护多个index,导致效率低下)
PS:这里有一个关键点,就是cluster index是无论如何都会存在的。(不管你有没有创建其他index,每个表都会存在一个cluster index)
根据网上很多的文章,都提及到一个内容:InnoDB只有在使用index的时候才是使用行锁,否则会变成表锁。这句话是错误的。因为即使我们没有创建index,在select的时候也没有使用index列,那么一样会使用一个隐式创建的cluster index去寻找数据,所以InnoDB只存在行锁,不存在表锁。
官方文档:
Record Locks
A record lock is a lock on an index record. For example, SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE; prevents any other transaction from inserting, updating, or deleting rows where the value of t.c1 is 10.
Record locks always lock index records, even if a table is defined with no indexes. For such cases, InnoDB creates a hidden clustered index and uses this index for record locking. See Section 15.6.2.1, “Clustered and Secondary Indexes”.
可是很多人表示自己亲自测试过,发现确实是整个表都锁住了呀,难道不是表锁吗?这主要是因为对底层了解不足,只开了两个session发现无法同时select就感觉是整个表都锁起来,是不正确的。这时候最正确的做法是:查看MySQL的状态表,查看当前存在的锁,然后直接查看锁的类型。毕竟网上说的都不权威,但MySQL它自己创建的表是最权威的!
我们这里创建两个session,发现存在lock,waiting的情况,这时候在另一个无须waiting的session执行: use information_schema; 进入到MySQL自带的information_schema数据库中
然后执行: select* from innodb_locks; 即可找到当前存在的locks。
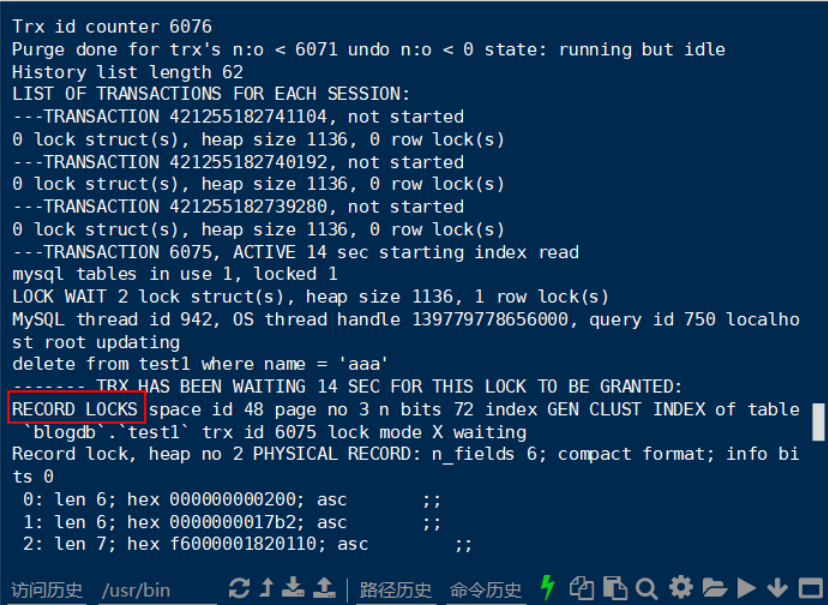
(也可以使用 show engine innodb status;查看,不过可读性较差,需要仔细观察)
下面给出两个命令的结果:(第一个是select* from innodb_locks;)
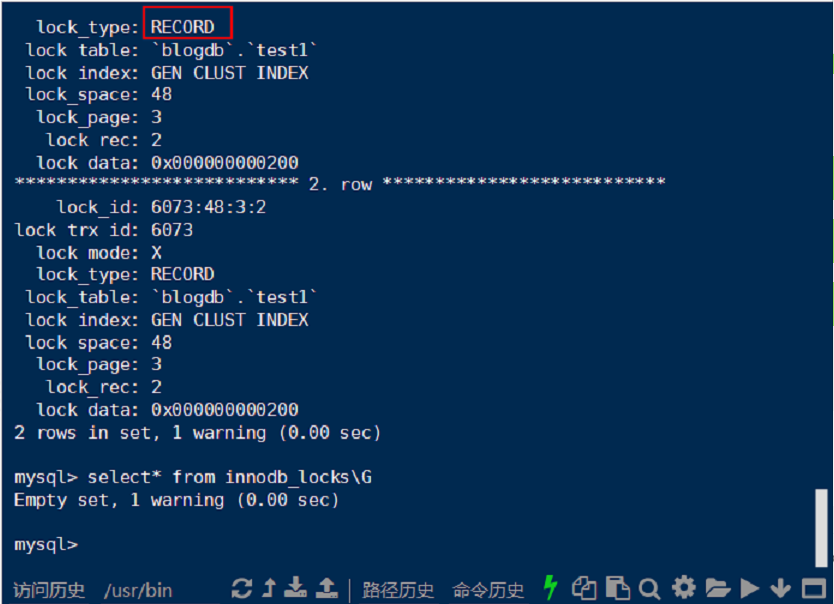
PS:MySQL8.0与之前的版本不一致(5.7及以前)。如下:(如果不是使用8.0可以跳过)
MySQL5.7及之前,可以通过information_schema.innodb_locks查看事务的锁情况,但,只能看到阻塞事务的锁;如果事务并未被阻塞,则在该表中看不到该事务的锁情况。
MySQL8.0删除了information_schema.innodb_locks,添加了performance_schema.data_locks,可以通过performance_schema.data_locks查看事务的锁情况,和MySQL5.7及之前不同,performance_schema.data_locks不但可以看到阻塞该事务的锁,还可以看到该事务所持有的锁,也就是说即使事务并未被阻塞,依然可以看到事务所持有的锁(不过,正如文中最后一段所说,performance_schema.data_locks并不总是能看到全部的锁)。表名的变化其实还反映了8.0的performance_schema.data_locks更为通用了,即使你使用InnoDB之外的存储引擎,你依然可以从performance_schema.data_locks看到事务的锁情况。
那么为何RECORD LOCKS会表现出类似于表锁的形式?这是因为InnoDB在没有使用index的时候,会使用cluster index(所以依然是行锁)此时会生成record locks和gap locks,并且是把每一个record,每一个gap都锁住,表现形式就像是整个表都被锁住的情况(但仍然是行锁)。
有的人可能觉得,这不是在挑文字游戏?并不,因为只有在特定情况下,才会出现这种情况,当我们修改一些其他参数,或者使用不同的index,都会出现不同的情况,到那时候就不再是整个表都锁住了。这个在最后的时候会详细说明,现在只需要知道,InnoDB,绝对不存在Table locks。
四. 不同情况的加锁处理分析
有了这些准备,我们开始讨论不同情况的加锁处理分析(加不加锁,加哪种锁)
此处参考了大佬的文章:http://hedengcheng.com/?p=771
情况①:简单的snapshot read: select* from table where id = 1;
这时候一般不加锁。但上文也说了,存在例外,那就是当事务隔离级别为Serializable的情况下,由于每一个操作都完全串行化,因而也不存在snapshot了,该操作会升级为current read,因而需要加锁。(同时,Serializable的情况下,MySQL的并发控制协议会从MVVC降级为Lock-Based。一般除非系统冲突非常严重,否则不采用Serializable)
有了第一个情况,可以发现加锁的情况是要考虑其他因素的,不能仅仅是给一个SQL语句就问获得了什么锁,还要考虑很多种情况。一般而言,需要考虑以下几种情况:(假设搜寻的字段为id)
1.id是否为主键?
2.当前系统的隔离级别是什么?
3.id如果不为主键,那么它是否存在index?
4.如果id存在secondary index,那么这个index是否是unique index?
5.两个SQL的执行计划是什么,索引扫描?全表扫描?(这里我是参照大佬的文章来写的,但个人认为第五点其实跟前面的重叠了。如果id为主键,那么就是采用了cluster index,即全表扫描。如果id不存在index,同样是采用cluster index。如果id存在index,无论是否是unique,都为索引扫描。)
现在给定一个表: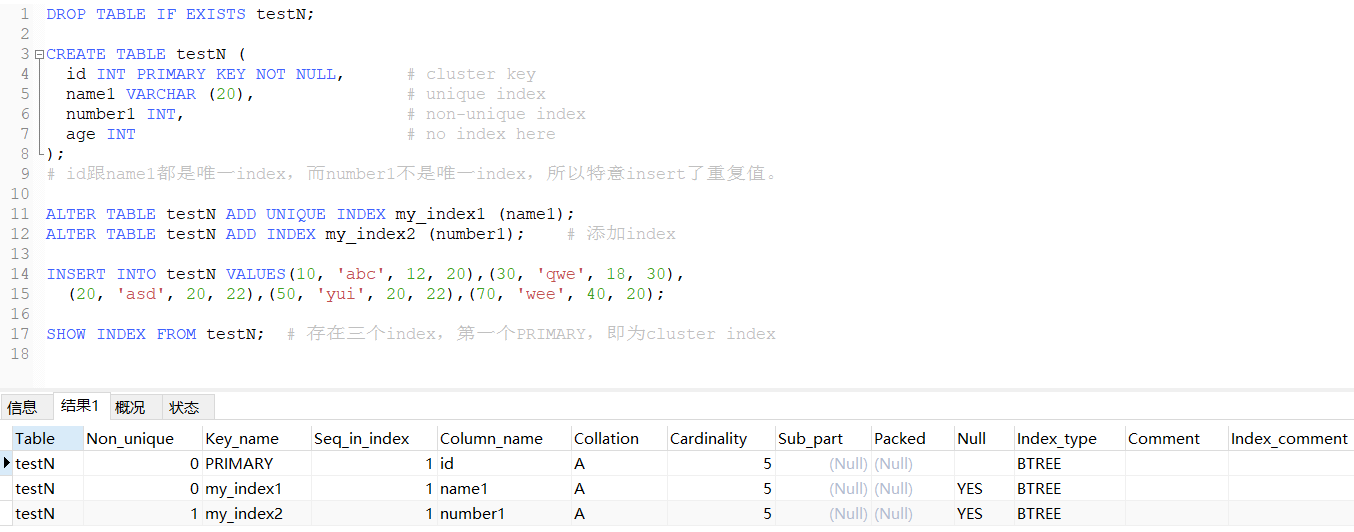
对于上面的几种情况,不一定每一种都排列组合一遍,把关键的点get到即可。
下面通过8种情况来考虑:
①~④:RC级别
⑤~⑧:RR级别
①搜寻字段是主键(PK)
delete from testN where id = 10;
此时其他事务无法访问id = 10这一行记录
情况最简单,直接在主键上id = 10的记录上加上X锁即可(在id字段上锁)。
②字段不是主键,但存在一个unique index。
delete from testN where name = 'abc';
同样无法访问name = ‘abc’这一行记录,但同时在id和name1字段上锁。
这种情况下,由于存在index,所以会在index上查询,这时候会给unique index加上X锁。同时当select的时候,如果没有指定secondary index的字段(*号也不行),那么还会到cluster index里去顺序查找。具体看图:(在上面最开始讲到cluster index里的文章就有具体说明)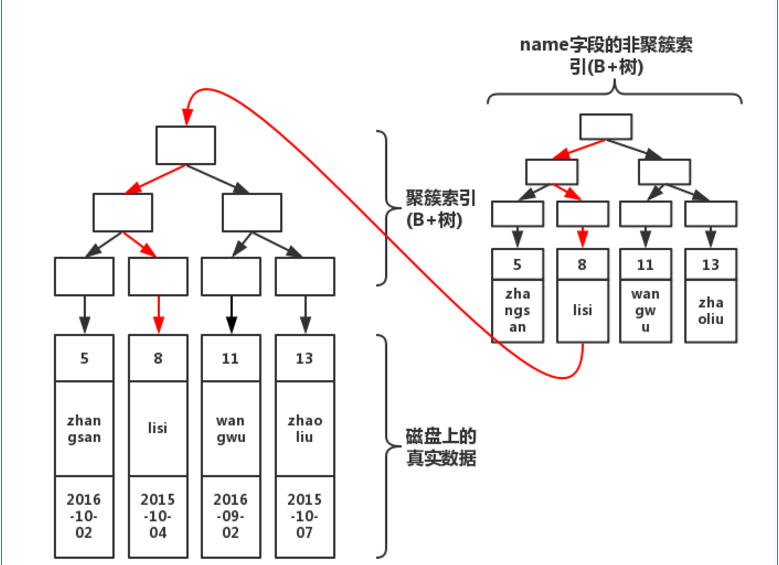
所以这个时候,除了给secondary unique index进行加锁,还会对cluster index进行加锁。
所以此处是给id,name1字段都加上了锁。(当然,被加锁的record依然是那一条,因为unique)
为什么聚簇索引上的记录也要加锁?试想一下,如果并发的一个SQL,是通过主键索引来更新:update t1 set id = 100 where name = ‘d’;此时,如果delete语句没有将主键索引上的记录加锁,那么并发的update就会感知不到delete语句的存在,违背了同一记录上的更新/删除需要串行执行的约束。
③字段不是主键,而且字段存在一个index,但并不是unique index
delete from testN where number = 12;
这种情况其实跟第②种情况是类似的,只是可能锁住多个record(因为不是unique index)
同样也是对number(index列)进行了加锁,然后还会对cluster index列加锁。
PS:看起来②和③可以归并在一起,但在RR的时候可以看到很大的不同。
④字段不是主键,而且不存在index。
此时会使用cluster index进行扫描,即全表扫描。而且会把所有的record都锁住。因为该条件无法通过索引快速过滤(暂且把cluster index视为很特殊的index吧,不然你都不需要自己创建index了),这时候在存储引擎层面就会将所有的记录加锁后返回,然后由MySQL Server层进行过滤。这是由于MySQL的实现所决定的。(在实际的实现中,进行了一些优化,在过滤条件中,如果发现不满足条件,那么在中途就会把不满足条件的记录释放锁。这样避免了把所有record都锁住导致的低并发,但也违背了二阶段锁的约束。这样最终持有锁的,会是满足条件的记录。但那大概是在事务提交执行的过程中,所以本地编写事务但不commit,依然会表现为全部记录加锁)
⑤搜寻字段是主键(PK)
跟①没有区别
⑥字段不是主键,但存在一个unique index。
跟②没有区别
⑦字段不是主键,而且字段存在一个index,但并不是unique index
有区别了,为什么?RR相对于RC,解决的问题是幻读,不可重复读。为何⑤跟⑥的加锁却没有任何改变?幻读,不可重复读是指当前事务,连续执行两次current read,返回了不同的数据。而⑤和⑥都是unique index,能够保持唯一性,不用担心值会发生改变(改变值需要X锁,与S锁不兼容)。
那么在⑦的时候,字段存在了index,但该index并不是unique index,这时候问题就出现了,如果还是按照③的做法,那么就可能出现幻读跟不可重复读的情况。
举一个例子,按照我们上面给的table的来示例:(假设采用③的只对record进行加锁的模式)
字段名为: id, name1,number1, age (PK为id)
执行的current read的语句为:select *from testN where number1 = 18 for update;(number1是非unique index列)
那么假如当我们在另一个session执行:insert into testN values(xx,xx,18,xx); commit;
这时候该session中的 transaction是可以成功提交的,因为并没有gap lock,而只是把原本符合条件的 record给锁住了,而不是把所有number1=18的都锁住。
这时候再次执行 select* from testN where number1 = 18 for update;就会出现幻读。
因此,此时会锁住符合记录与相邻记录的间隔。这个就称为间隔锁:gap locks
假如:字段的取值是:12,32,18,18,20,24,30.选择的条件是 id = 18
那么除了锁住两个18的记录,还会锁住12与18,18与20之间的间隔(有序性)
所以此时锁住的范围:record locks: 18, 18
gap locks: [12, 18) ∪ [18, 20)所以整体锁住的范围就是: [12, 20)
⑧字段不是主键,而且不存在index。
⑧跟⑦不一样的地方是,⑦会把符合条件的record的与前后record的间隔都给锁住,而⑧由于是全表搜索(无index,只有cluster index),因此⑧首先是把所有的records都锁住,然后再把所有records的间隔都锁住(包括±∞)。假如age列(非index列)一共有20,22,30等三个值,那么由行锁record locks和间隔锁gap locks锁住的范围为:
(-∞, 20) ∪ [20, 22) ∪ [22, 30) ∪ [30, +∞)(因为表现为整个表都锁住了,所以容易误以为是表锁)
(虽说误以为是表锁是错误的理解,但确实要尽量避免这种情况,因为这种情况需要加很多锁。当该非index列有n个records的时候,需要加n个record locks,(n+1)个gap locks,一共需要(2n+1)个锁,开销是极其大的。所以尽量通过index来查询,避免加入过多的锁,影响性能。
附:测试
数据以上面的testN的数据为例,事务自动提交设置为否:set autocommit = 0(除了在阐述③如何引起幻读的情况下,需要commit,其余都无须commit,只需要显示到被锁住即可。并且这一步会放到最后执行,前面的每一项测试,在测试完毕之后,都执行rollback,避免事务对数据的更改)
初始数据: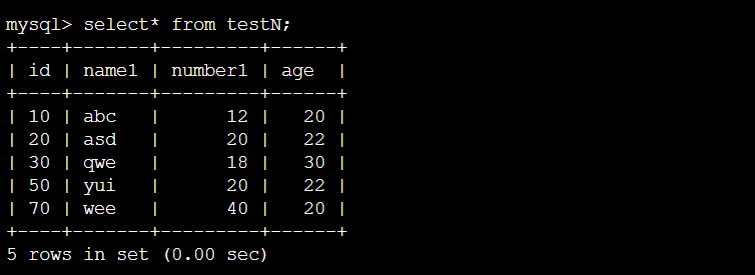
确保环境:(1~4在RC,5~8在RR。虽说应该是global才生效,但直接把session跟global都设置一遍) (两个终端都设置)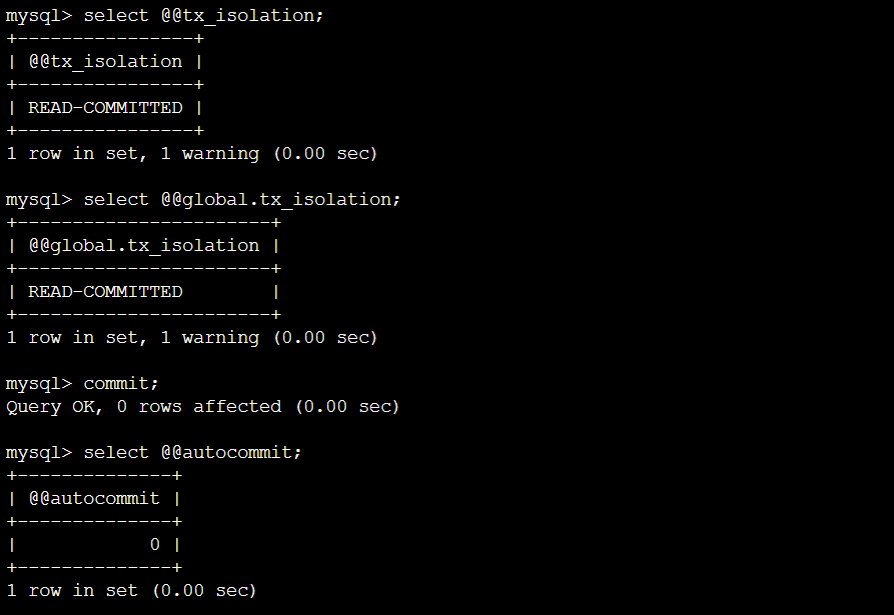
情况①:
终端A: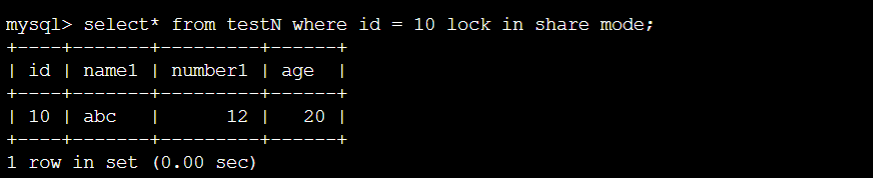
终端B: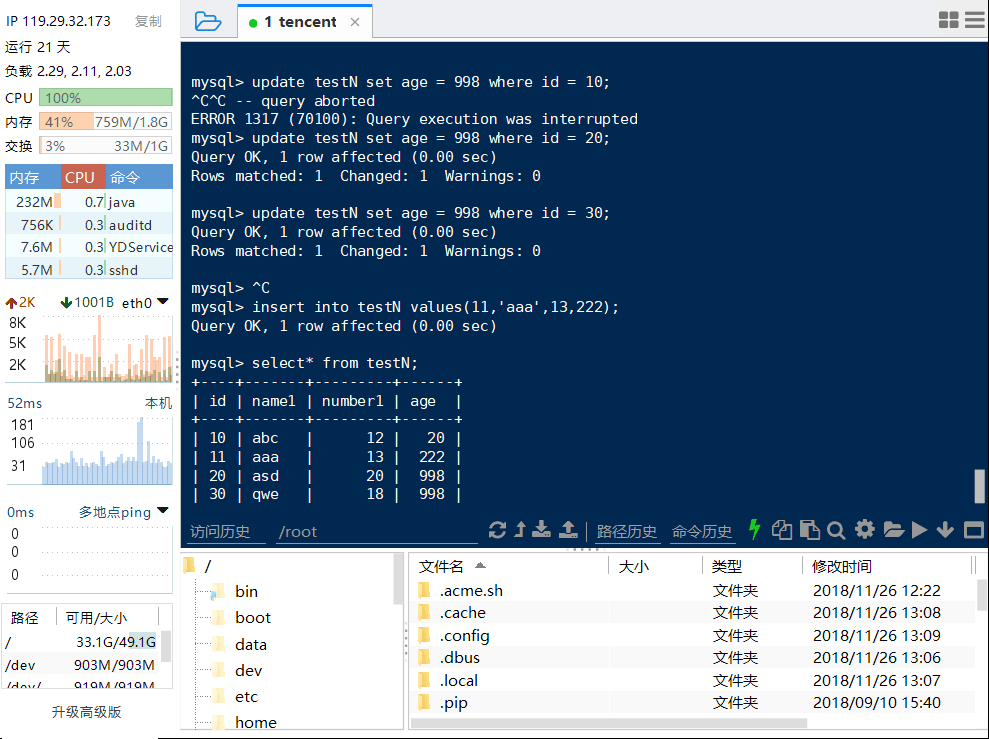
结论:①确实只锁住了id为10的那条记录,其他所有都没有锁。
情况②:
终端A: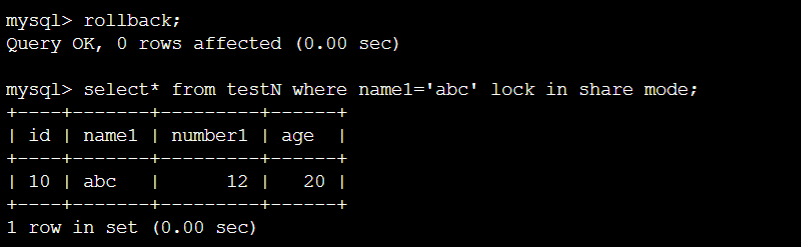
终端B: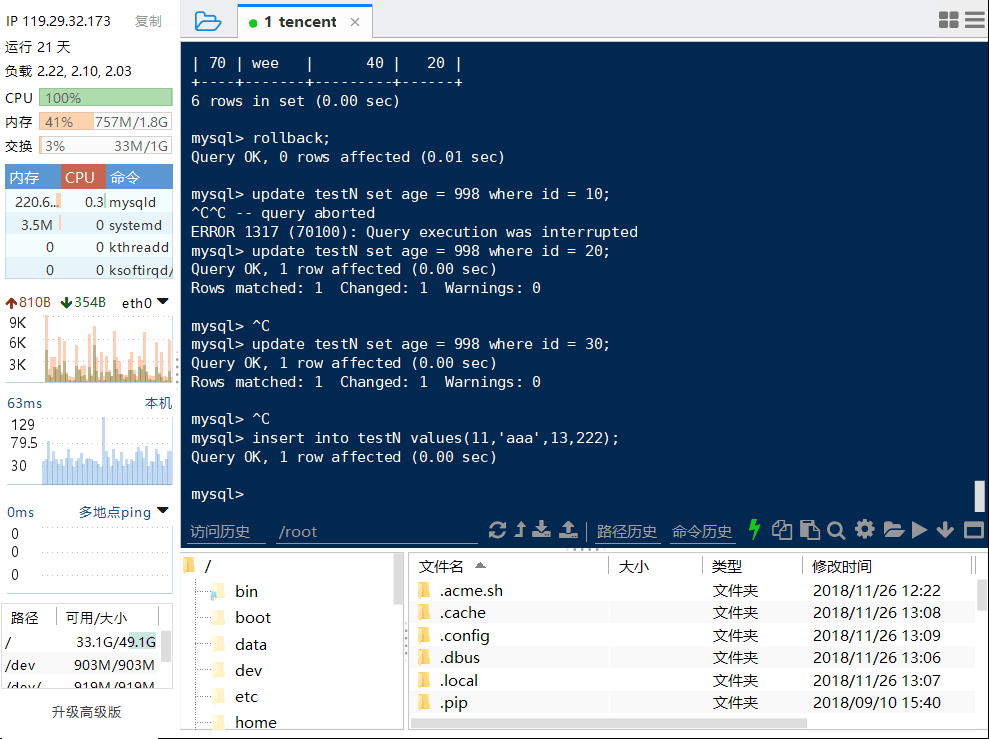
结论:②确实也是只把name1=’abc’该列锁住了。没有其他任何的锁。
情况③:
终端A: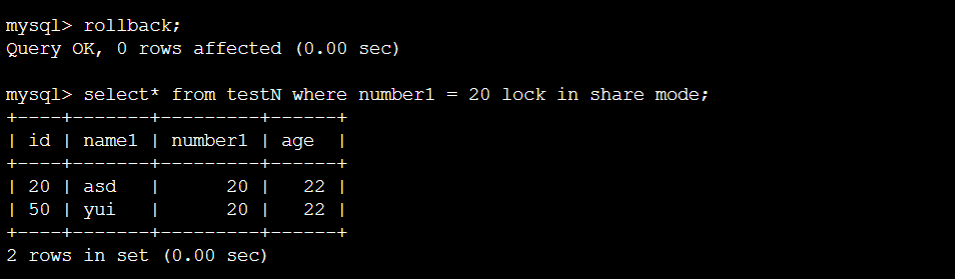
终端B: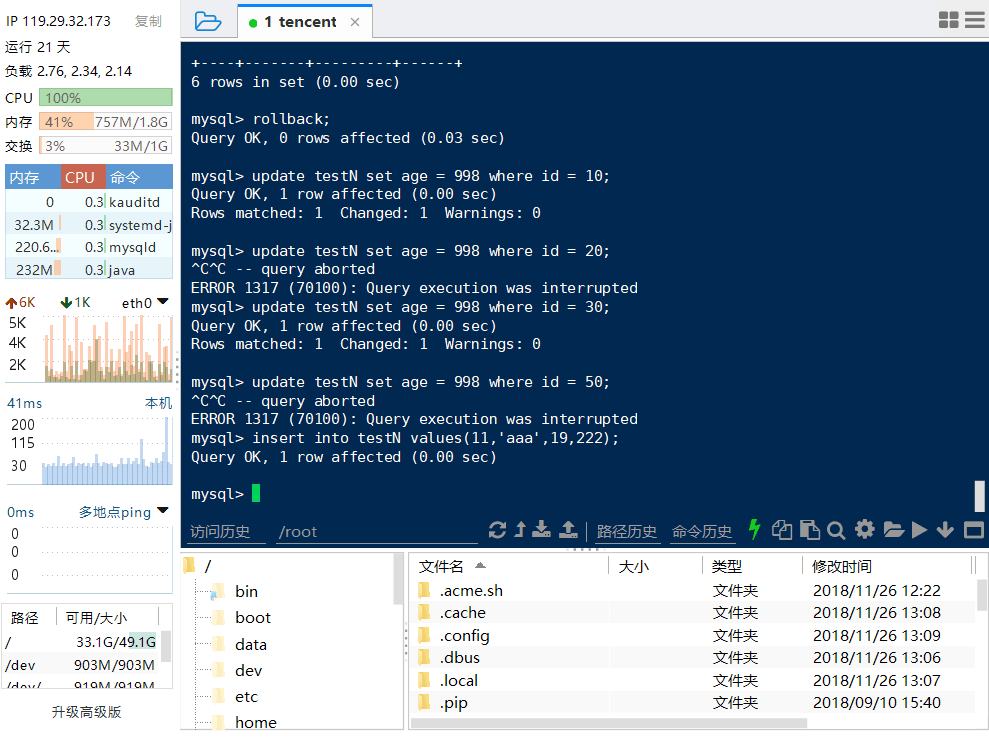
结论:③,number1为20有两个记录,这两个确实都被锁住了。而且其他都没有锁住,没有gap locks
情况④:
终端A: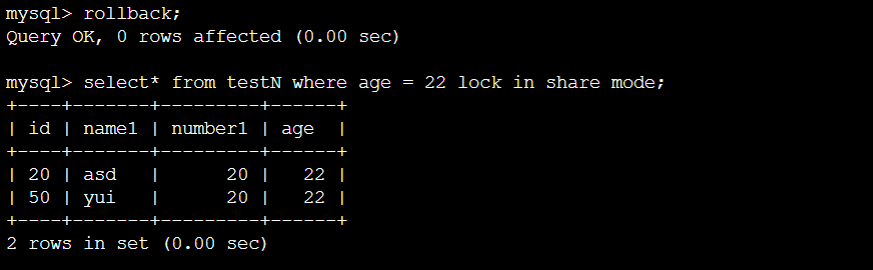
终端B: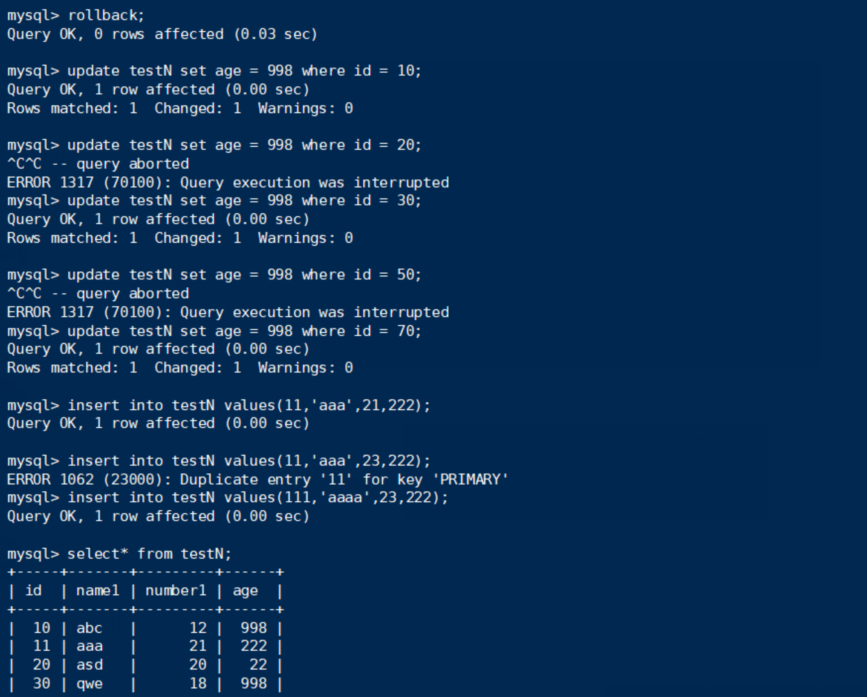
结论:④理论上是锁住所有record,但在判定不符合之后就把锁释放了(即那个违背了二阶段锁的优化操作),所以最后只把age为22的锁住了。
RC环境转RR环境:
终端A: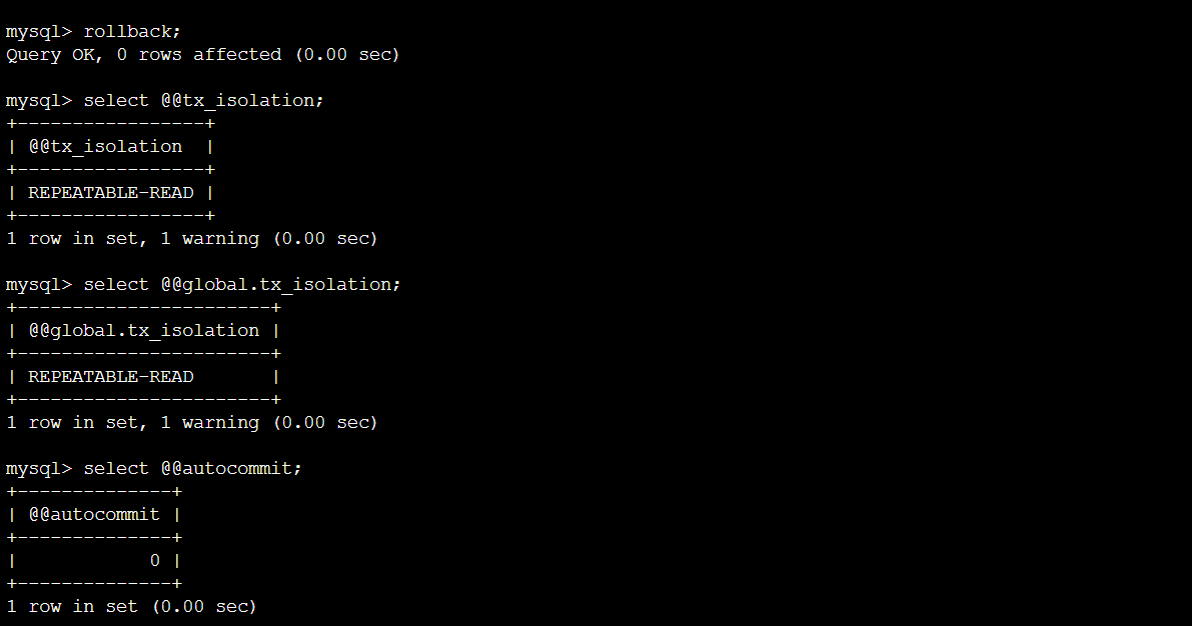
终端B: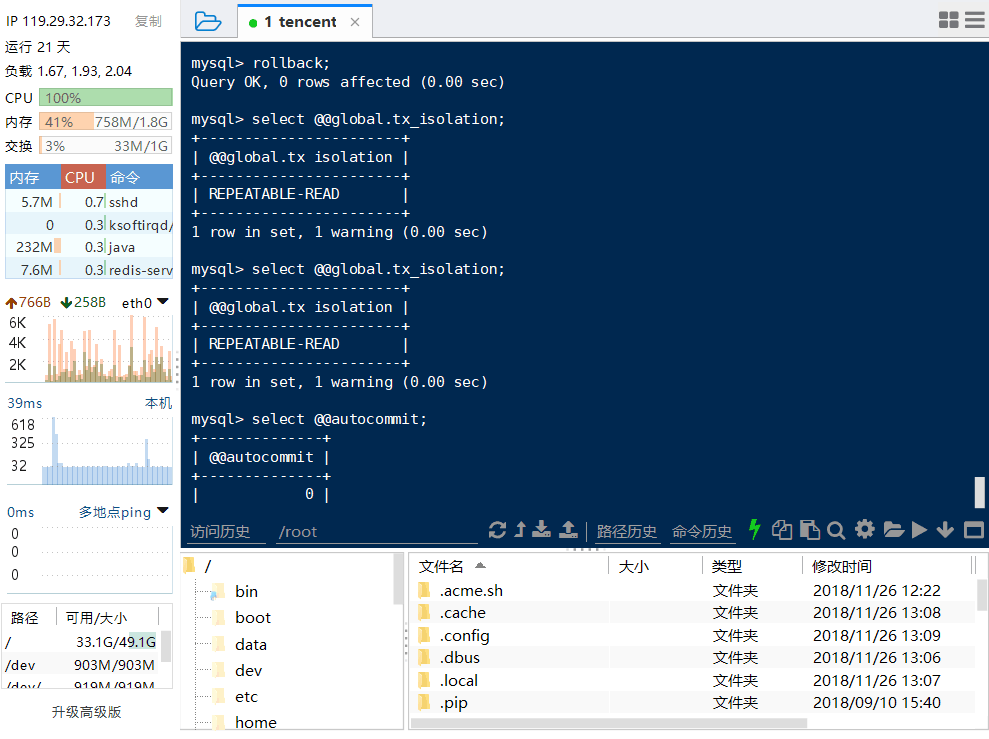
情况⑤:
终端A: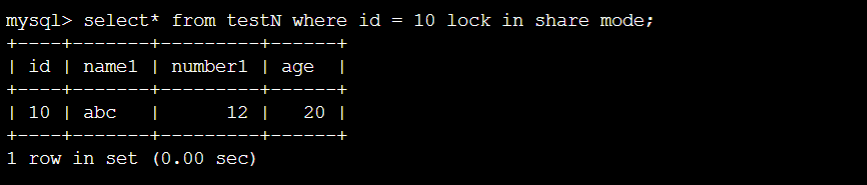
终端B: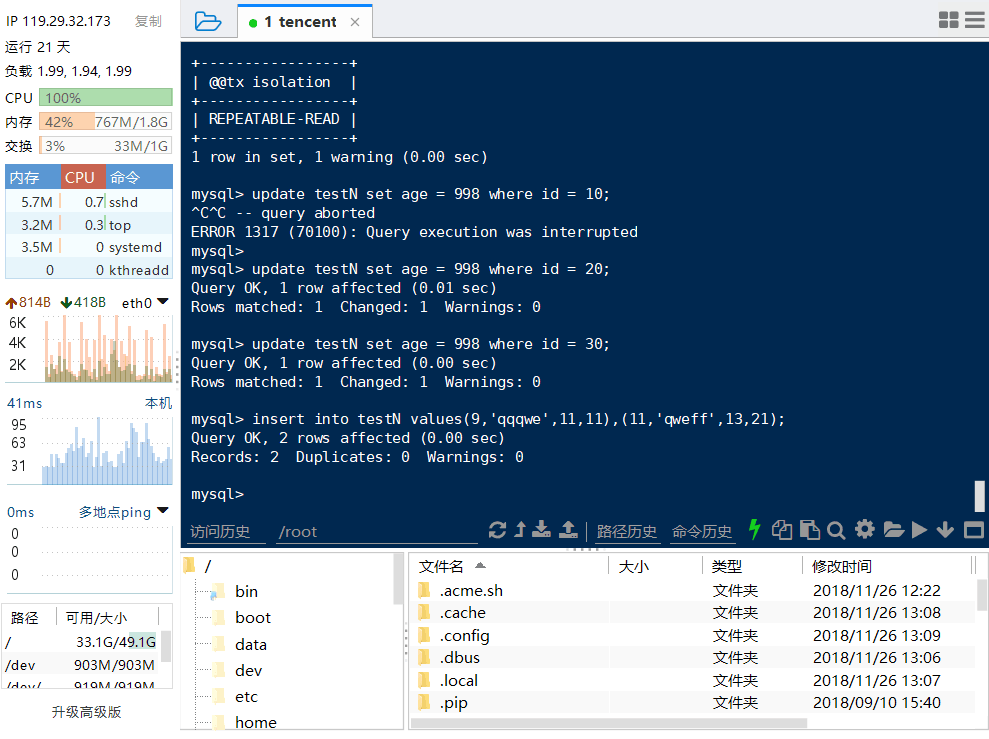
结论:⑤与①相同,没有任何变化。
情况⑥:
终端A: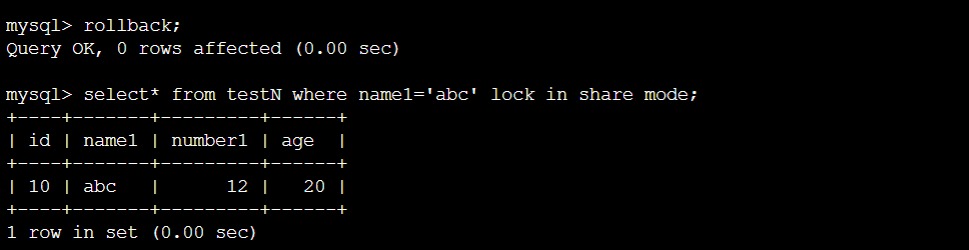
终端B: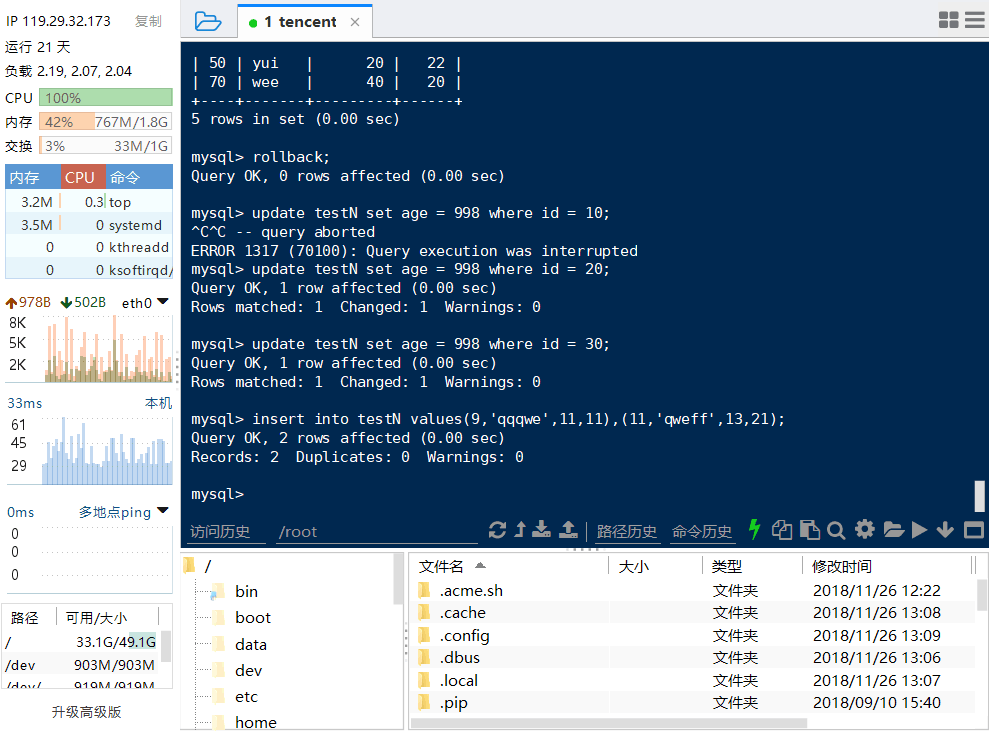
结论:Ⅵ与②相同,没有任何变化。
情况⑦:
终端A: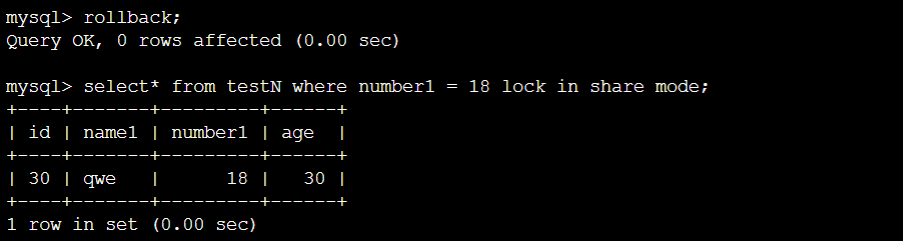
终端B: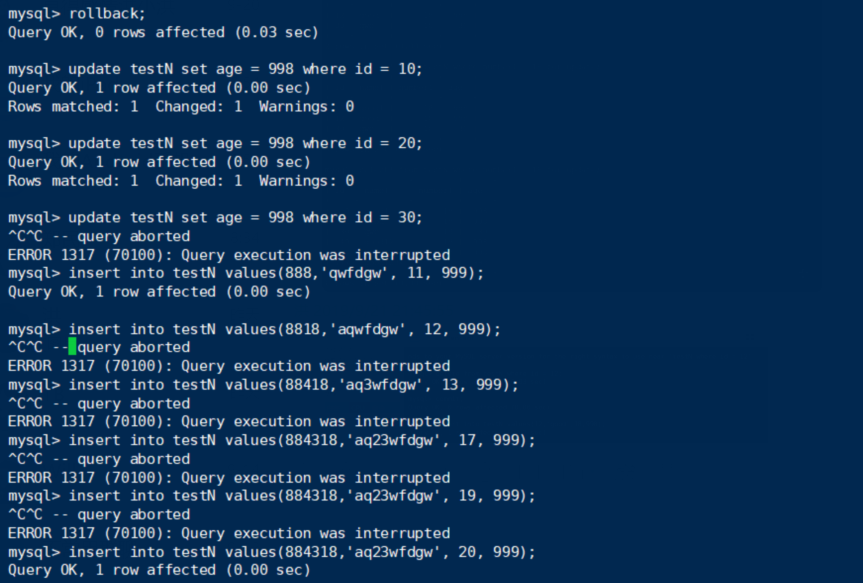
锁住18,与预期相同。18相邻的元素为12,20,因而把 [12, 18)∪ [18, 20)给锁住了。(锁的范围是左闭右开,因而12无法insert,但20是可以insert的)
下面再测试锁住20的情况。
终端A: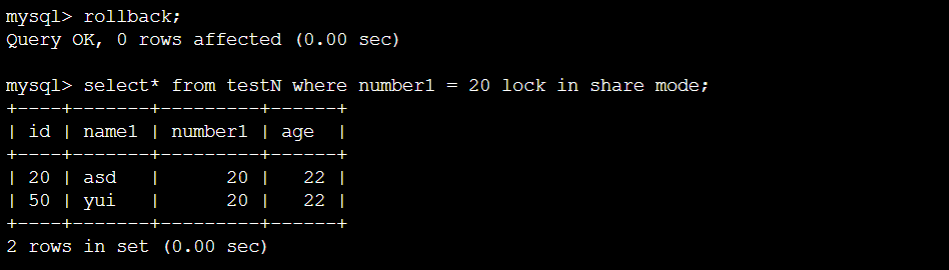
终端B: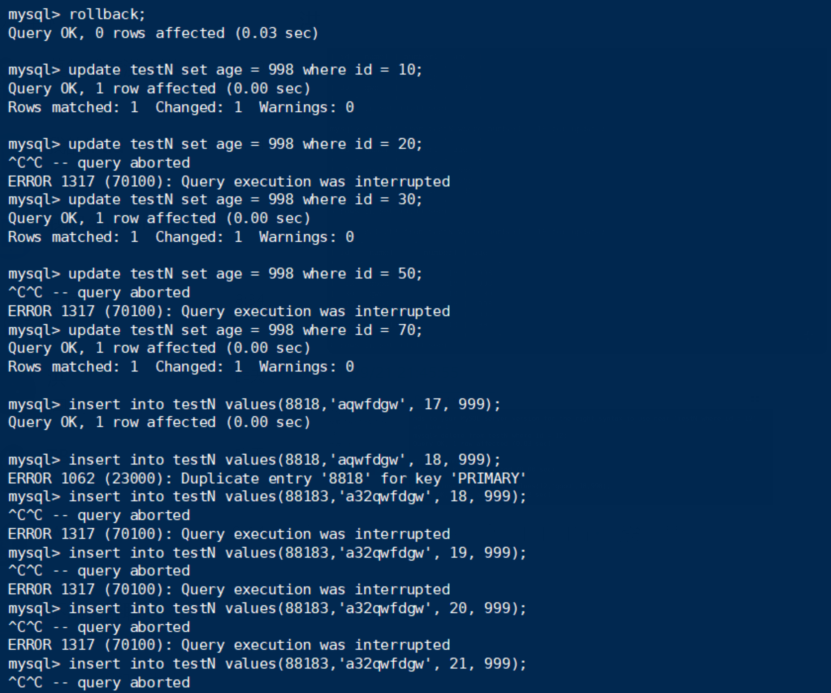
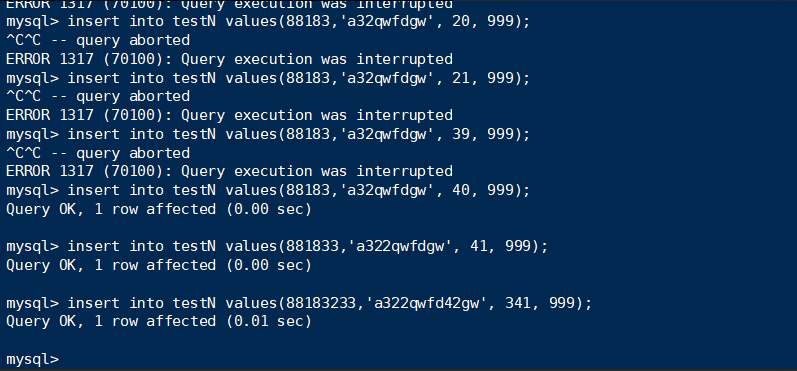
锁住20,同样跟预期相同,会把[18, 20) ∪ 20 ∪ [20, 40)都锁住
假设选择的值是最小/最大,是否也像no index的情况下,锁住±∞?
终端B:
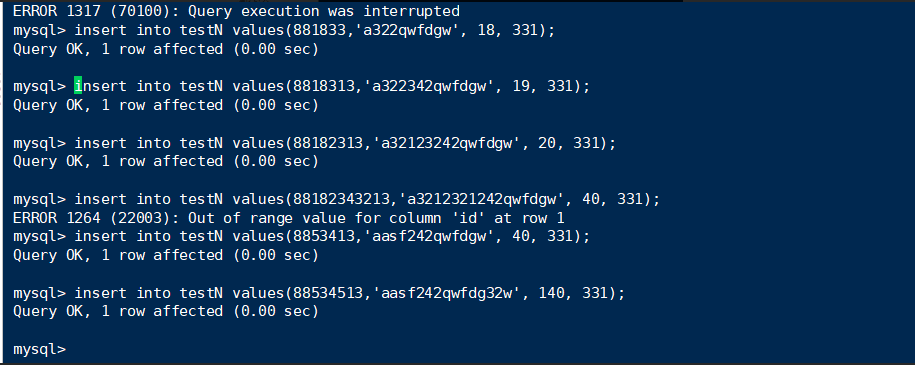
答案是会的。所以也跟预期一样。
结论:⑦与③不同,在RR的情况下会使用gap locks,锁住间隔。
情况⑧:
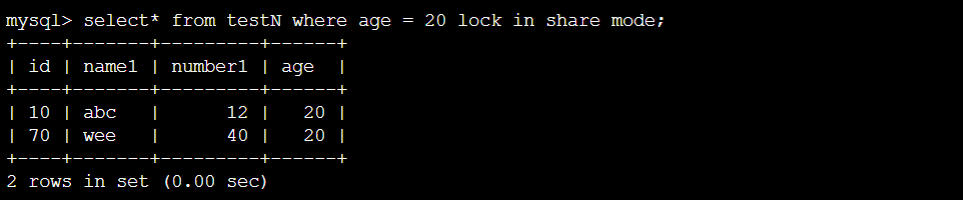
终端B: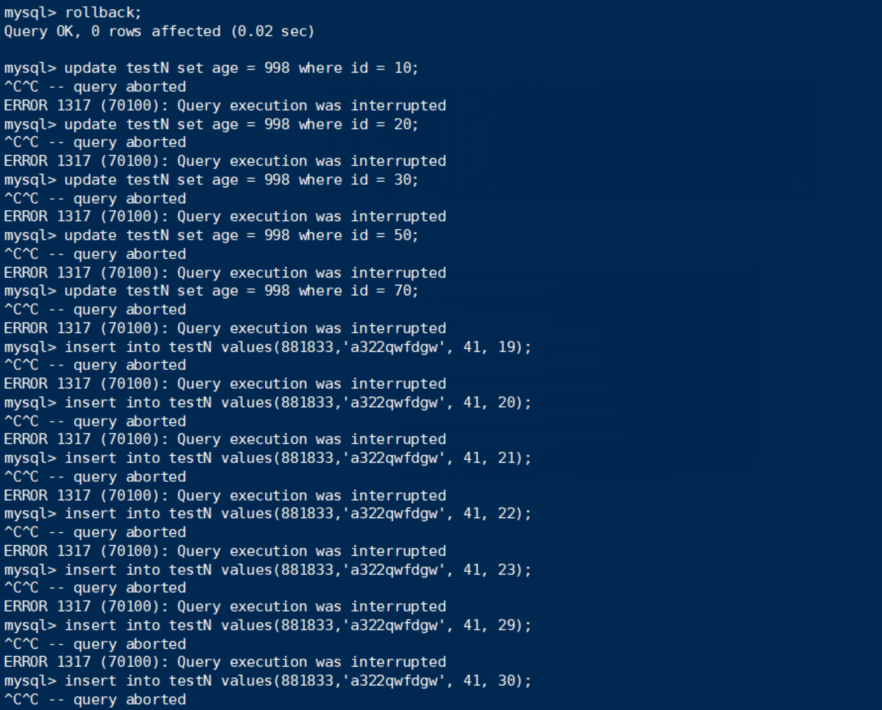

表就像完全锁住一样,因为record locks & gap locks 把整个表都锁住了。
结论:⑧在RR的情况下,会把所有的record都锁住,也会把所有的gap锁住。
最后,测试RC环境下,③可能会导致幻读的情况:(RR已经确定不会出现幻读)
环境参数:(RR改回RC)
终端A:
终端B: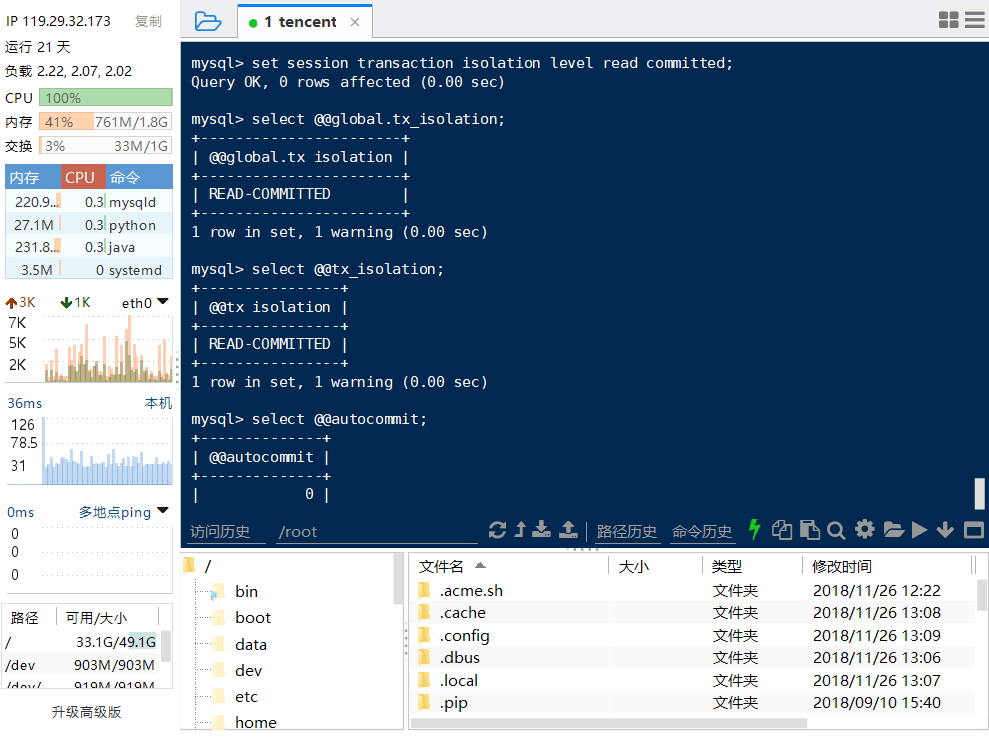
终端A: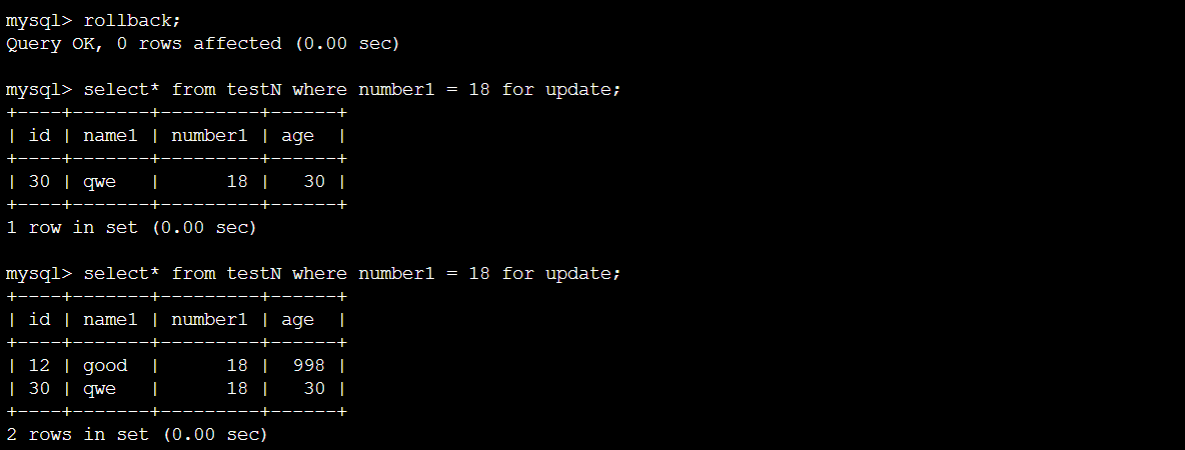
中间,在另一个终端B执行:
可见session1的lock并没有锁住session2创建number1为18的值。只要unique行没有duplicate,那么就可以insert,insert更多例子:
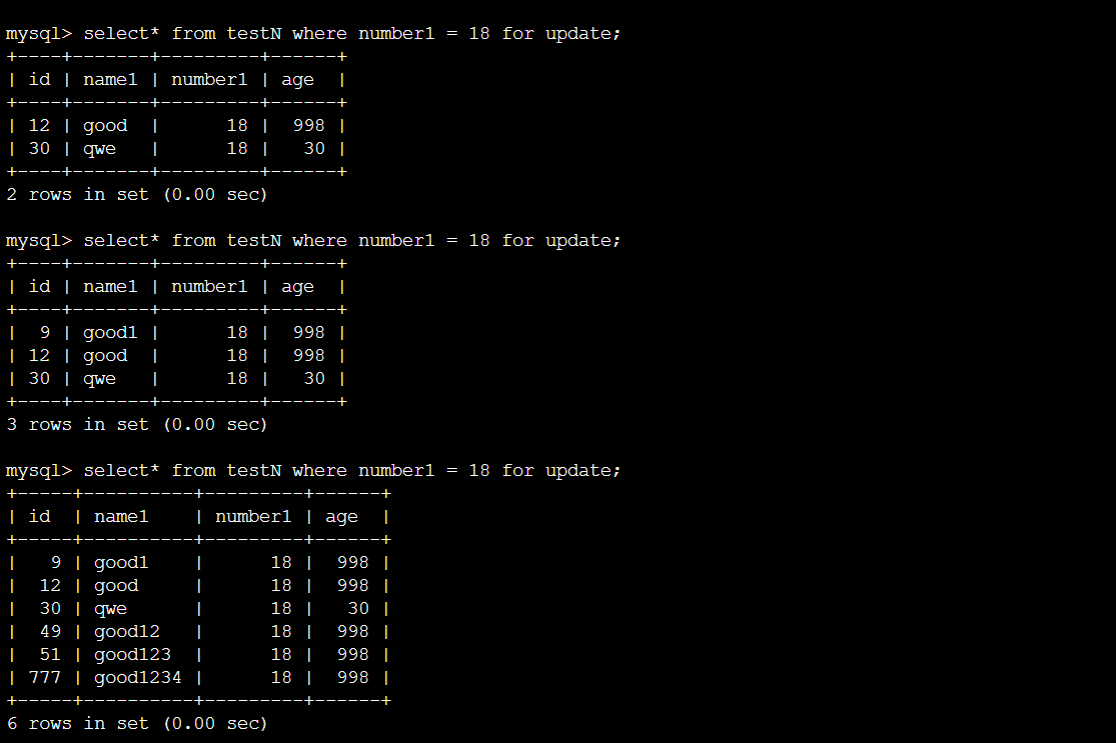
PS:以上讨论的是什么时候加锁。至于加什么锁,应该很好判断。如果是select lock in share mode,那就是加S锁,select for update,就是加X锁。
当范围比较的时候,又有所不同!当范围比较的时候,又有所不同!
(上面考虑的都是等值筛选的情况) 以下就不考虑等值的情况
使用数据: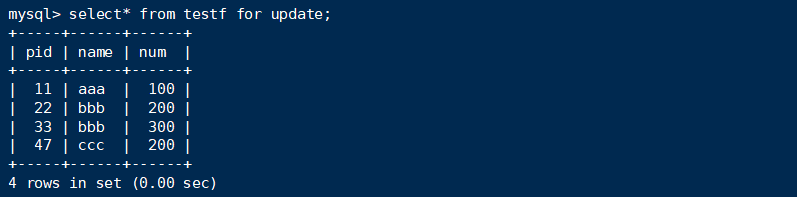
①使用PK的情况(cluster index)
SQL句子: (用4个句子来解释)
1 | select* from testf where pid > 30 for update; |
对于RC:
句子1:首先符合条件的记录为pid = 33, pid = 47.对这两个records加上X锁。
句子2:首先符合条件的记录为pid = 47,对着一个record加上X锁。
句子3:没有符合条件的记录。
句子4:两个符合,加锁。
此时执行select:句子1可以获取pid = 11,12,的记录,句子2可以获得11,12,33,句子3全部可以
此时执行insert:除了相同的pid(duplicate),没有任何限制。(但insert相同的pid时,还是会起冲突哦。先是waiting获得lock,然后获得了之后才发现,duplicate,insert失败。即添加被record lock锁住的记录,仍然要waiting,而其他就无须获取锁的就直接duplicate。下同)
对于RR:(增加gap locks)
句子仍然对符合的records加上X锁,之后,开始增加gap locks:
句子1:
gap locks:对于 pid > 30,因而需要找一个左边界,找一个左边最接近30的record,在这里即为22.因此,gap locks的范围:[22, 33) ∪ [33, 47) ∪ [47, +∞)
对于insert,不能insert record locks & gap locks范围里的pid。合理。
对于select,也还是跟RC情况一样。因为被record locks锁住的在RC就不能访问,而被gap locks锁住的范围无法insert,因而select也肯定是empty set。那么,就不会出现幻读。
句子2:
与句子1的唯一区别是,33刚好就在表里,那么左边界到底是22还是33?
好的,答案是33,因为判定条件≠33啊。剩下的也就一样了,gap locks:[33, 47)∪[47, +∞)
句子3:
这个有点特别的是,没有record。但其实是一样的,找边界,因而这里这里的边界显然就是47,gap locks: [47, +∞)
句子4:
值得注意的是,左边界是无穷,右边界显然是33.但这里的右边界竟然是闭合的!
所以此处gap locks:(-∞, 33],因而只能insert 34之后的pid。所以select的时候就只能select 47了,33是不可以的。insert也不能包括33.
②不使用PK,使用unique index
修改了一下表的结构跟数据:num具备一个unique index
测试了一下,发现跟PK一模一样。懒得说。(内部实现实际上有区别的,如果说要什么区别的话,那就是上面刚开始说的①和②的区别啊!②会先给unique index加锁再给cluster index加锁。
(其实就是cluster index那一篇拓展文章)
③不使用PK,使用non-unique index 从这里开始很特别。
直接讨论RR:
1 | select* from testf where num > 200 for update; |
对于句子1:
终端A:
终端B: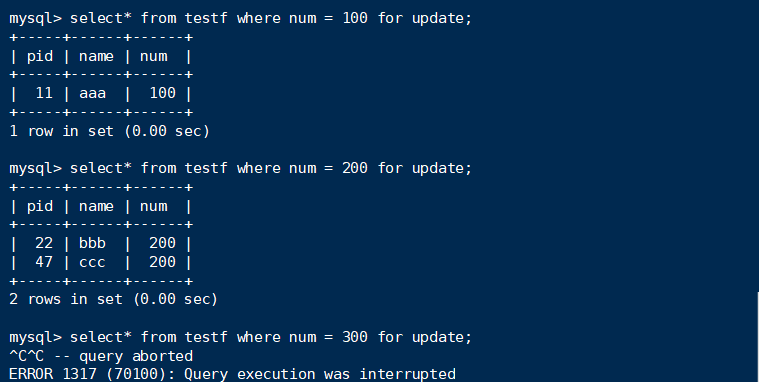
显然,select还是只把符合的记录给锁住了,即只锁住了300,100跟200均可select。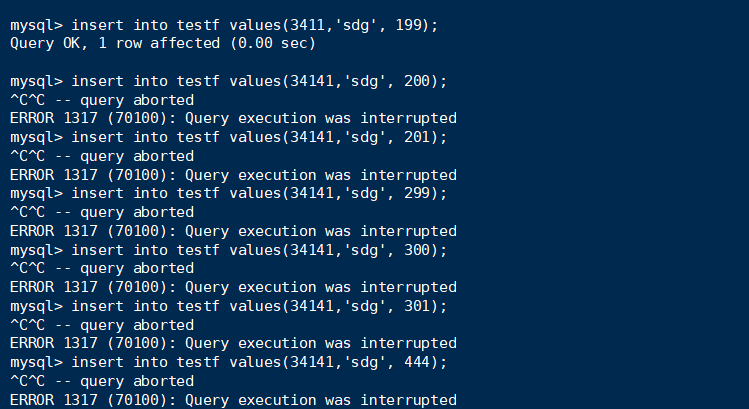
对于insert,依然是找到相应的边界值(这里显然是200),于是锁住了[200, +∞),因而可以insert 199
对于句子2:(看起来应该会跟句子1一样,但结果……)
终端A: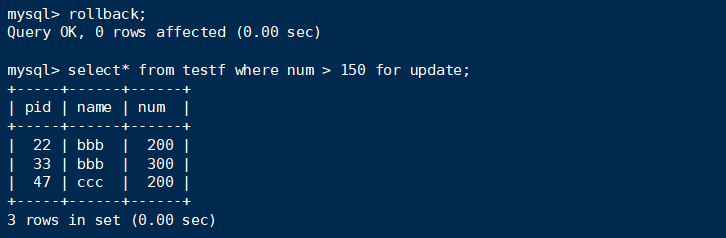
终端B: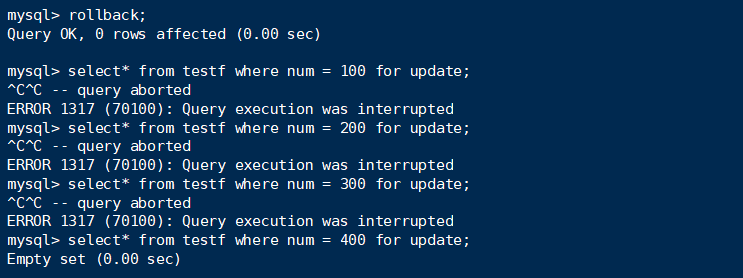
select竟然全部记录都获取不到了,除了不存在的空记录。那么insert呢?
既然已经是所有record都上锁了(record locks),那么理应把record之间的间隔也上锁(RR),结果insert确实如此,全部都无法insert。
(而句子1跟句子2的区别,仅仅只有150跟200,200存在于里面,而150不在。推测:索引为B+树类型,所以当存在相同的元素时,就可以直接根据B+树的有序性进行合理上锁,即对符合条件的记录上锁。那么如果不存在相同的元素,即不存在150,而且又不是unique index,仅仅是使用了一个non-unique index并且被动地去cluster index中查找,这时候就会把所有记录上锁,因为cluster index是一个特殊的index,具体的细节我也不懂,得去看源码。但现在只需要知道,cluster index无法标记到相同的元素,就无法进行定位了,然后就直接把所有record都锁了,当然在RR下还有gap locks)
对于句子3:
终端A:
终端B: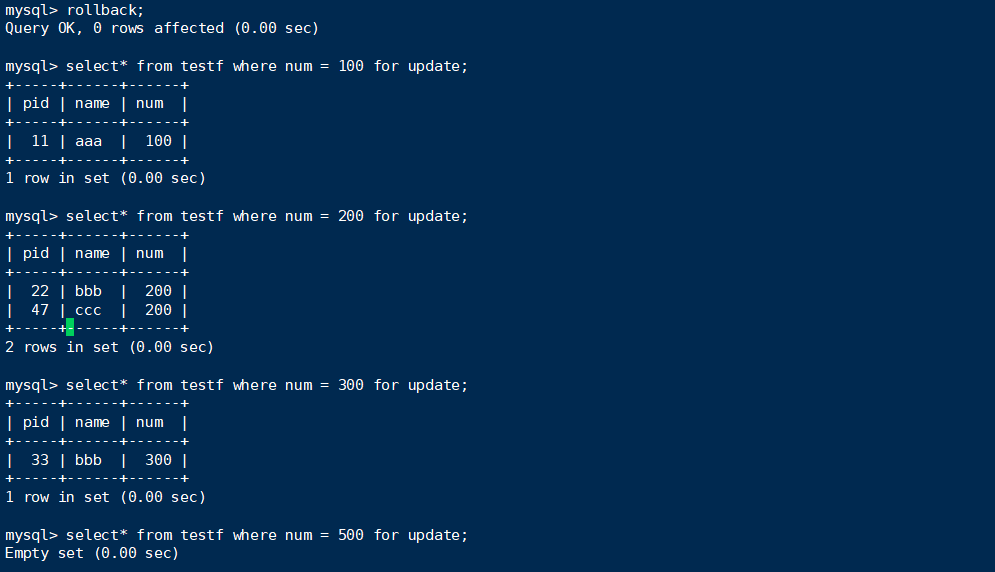
可见,由于里面没有符合条件的记录,所以select没有被阻塞。
可是,insert却是会被阻塞的。而且阻塞范围就是寻找边界。这里上锁的区域是[300, +∞)
(虽然400不存在于表中,但由于没有符合的记录,就没有把record给上锁了,所以也仅仅是添加了gap locks。但gap locks包含300,却只能search不能insert。看来只能看源码才能切实看懂了!先记住罢!)
对于句子4:
跟句子2是一样的,select全部锁住了,毫无意外的话,insert应该也会被全范围的gap locks给锁住。(// TODO = =!)
确实如此,就不贴图了。
本来不想测试RC的,但RR的结果有点出人意料,所以现在再把RC也测试一遍:
句子1:select还是一样,符合条件的锁住。insert没有任何阻塞(因为不存在gap locks)
句子2:跟RR的不一样,并不会全部锁住,而且也不会把记录都锁住。
select依然是符合条件的才锁住。而insert依然是没有任何阻塞(没有gap locks)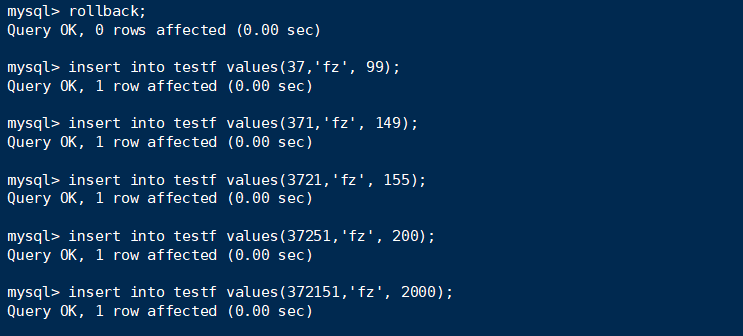
句子3:还是一样。select该锁的锁,insert无阻塞。
句子4:一样。pass
(RC的insert无阻塞是毫不意外的,首先RC不存在gap locks,至于已经存在的record则会因为PK/cluster index而产生冲突,并不是因为gap Locks)
情况④:不使用PK,也不使用index
RC:
1 | select* from testf where num > 200 for update; |
句子1: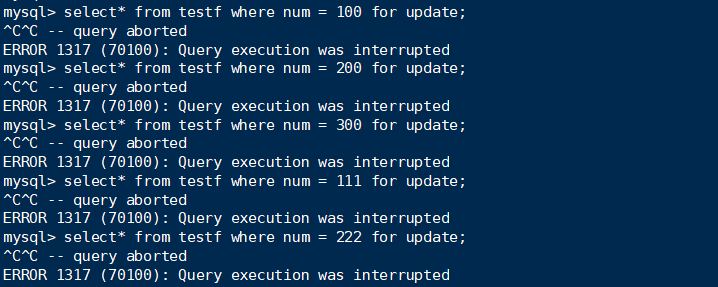
select全部锁住了,而且不仅仅是记录,包括gap。而RC是不存在gap locks的。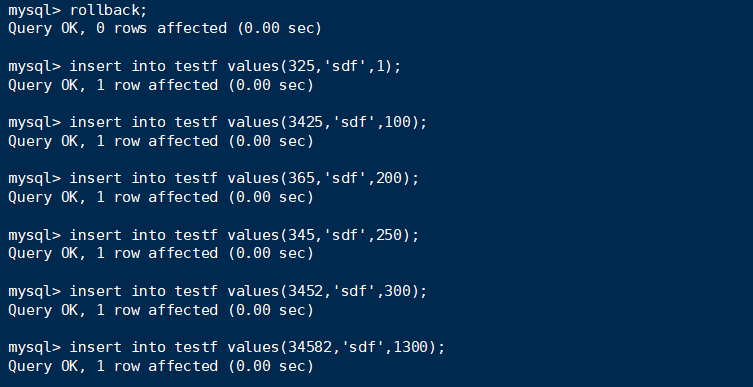
而insert却是依旧跟预期一样,毫无阻塞(因为RC没有gap locks)
句子2:select也是一样全部阻塞。而insert也是毫无阻塞
句子3: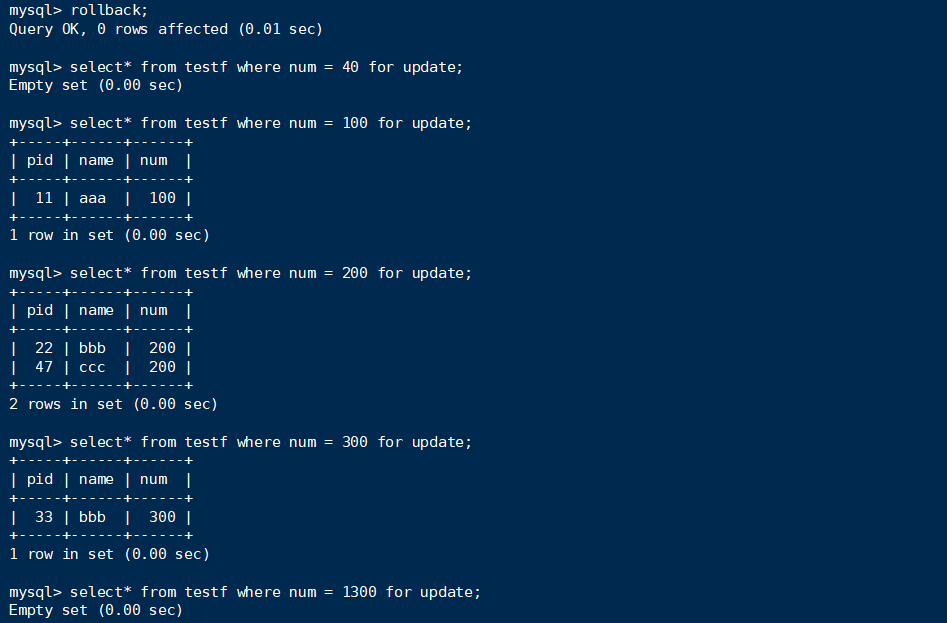
select毫无阻塞,因为没有找到记录。insert也是毫无阻塞。
句子4:还是那样,select完全阻塞,insert没有阻塞。
RR:
1 | select* from testf where num > 200 for update; |
句子1:
select依然全部被阻塞(RC都阻塞, RR岂有不阻之理?)
insert也是全部阻塞,因为RR多了gap locks,自然也就全部范围都锁住了。
句子2跟句子4显然结果也会是一样的。
那么再看句子3,竟然也是全部阻塞。
上面都是详细的推导环节,虽然还有所疑惑,但至少结果是没有错的,先总结了吧(关于insert并发这个,以后再说吧。这个应该满足了select/delete/update与insert之间的所有关系了,只差并发insert这一环节) PS : insert还有一个insert意向锁
总结:
分两大类情况:等值筛选(id = x),范围筛选(id > x)
以下操作只考虑select跟insert(delete跟update约等于select。)
先看等值筛选:
① RC / RR + PK
锁住该条记录的。select,insert均不能使用相同的字段值(insert是因为同名,select是因为锁)
② RC / RR + Unique Index
跟①一样,只是底层实现有所不同(先对Unique Index的记录加锁,再对cluster index的记录加锁)
③ RC + Non-unique Index
锁住所有符合条件的记录(因为不是unique,可能选出多条记录)
④ RC + No index(无索引)
锁住所有的记录(MySQL优化后,对判断不满足条件的记录,进行释放锁操作。违背了2PL协议)
⑤ RR + Non-unique Index
锁住符合条件的记录,并且新增gap locks。会锁住记录与其相邻记录的中间间隔(按照有序排列)
gap locks一般按照 左闭右开的原则。
⑥ RR + No index
锁住所有的记录,具备gap locks。因为所有记录都锁住,所以从-∞到+∞其实都被锁住了。
n条记录时,n个Record Locks, n + 1 个gap locks,一共 2n+1 个锁。
范围筛选:(PS:如果两个select都是S锁,那当然是可以同时存在的,S锁之间兼容)
① RC + PK / Unique Index / Non-Unique Index
(RC条件下,只要使用Index,无论是Unique Index还是Non-Unique)
锁住符合的记录,可以select没有锁的记录,insert无限制。
② RR + PK / Unique Index
锁住符合的所有记录,还有gap locks。同样是可以select没有锁的记录,insert无限制。
③ RR + Non-unique Index
Ⅰ. 当表中存在比较的值(即id > x, table存在 id = x的记录)
同①
Ⅱ. 当表中不存在比较的值(id > x, table不存在id = x的记录)
select全部阻塞(除了不存在的记录),insert全部阻塞(record已经阻塞,加上gap必然的结果)
Ⅲ. 当select返回的是empty set (例子:where id > 100,而table中不存在id大于100的记录)
同① (其实跟 Ⅰ 也是等价的,只是符合的记录为empty set)
④ RC + No Index
Ⅰ. select返回的值非空
select完全阻塞(包括不存在的记录也无法select),insert无阻塞(RC不存在gap)
Ⅱ. select返回的是empty set
select跟insert都没有阻塞
⑤ RR + No index
select跟insert必定全部阻塞。
PS:在RR的情况下,对于并非全锁的情况,Gap Locks的边界值考量方法都是一样的(都是找左右相邻最近的,即使你是empty set,那么就找table中最大/最小的那个当边界,都是一样的,此处略)
并且,此处主要考虑的是RC跟RR级别下的情况。对RU跟Serializable并无太多讨论。而且只考虑了select与insert,select与select之间的冲突(据说select跟delete,update都是一个形式,那么就略了),还剩下的是Insert与Insert之间的冲突,即并发插入,TODO吧。
PPPS:写完之后再整理,想到了大佬文章里的第五点,SQL语句的执行计划是什么?是索引扫描还是全表扫描?我当时认为这点可以忽略,因为我认为cluster index必定存在,所以即使是全表扫描也是等同于索引扫描,只是扫描cluster index的时候存在一点特殊(就是上文提到的那点)现在看来,cluster index虽然是index,但确实是特殊的index,当我们需要使用全表扫描,即使是使用了cluster index,也是不能完全等同于索引扫描的。想想最后在范围搜索那里,出现的意外情况无法理解的,应该就是这一点了吧。(因为当时的注意力主要在考虑InnoDB是否存在表锁,然后最后的主要论据就是必定存在cluster index,所以必定有索引,表现出表锁的特征其实是行锁加间隔锁的作用等等……实际上,这一点倒是没有错,但cluster index是特殊的index也不可忽视!)